Welcome to our Distributed Training project page!
Students: Cheng Wan and Haoran You
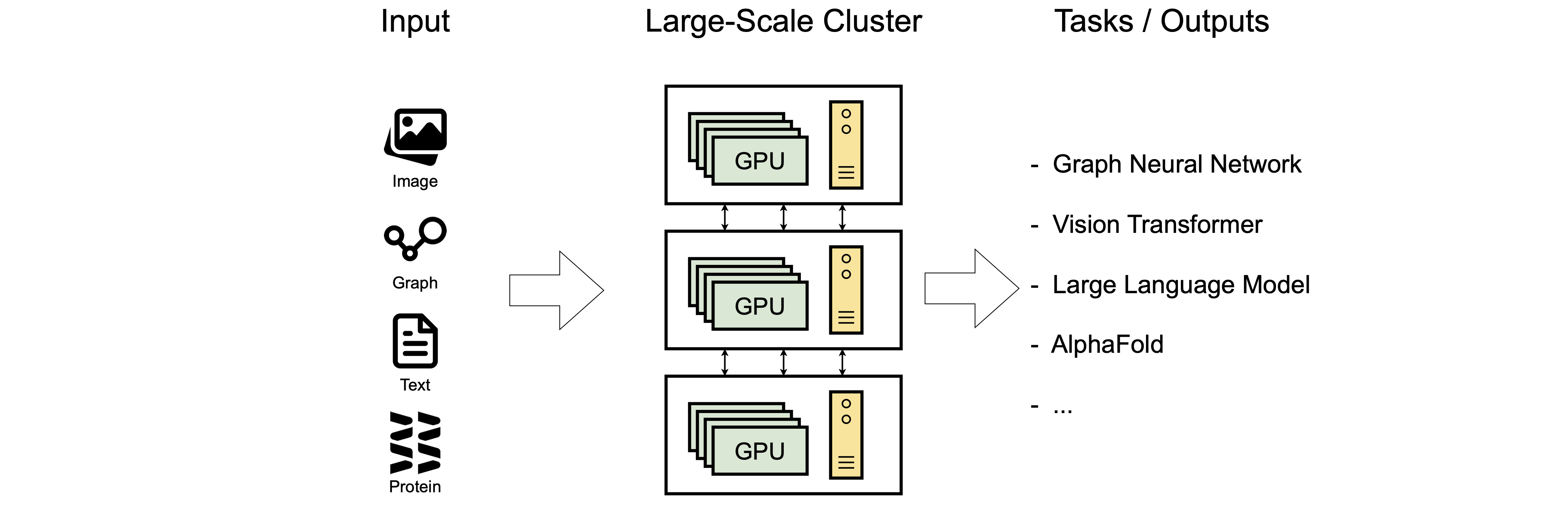
As machine learning rapidly advances, the size of both models and datasets is growing at an unprecedented rate. Our team is leading the way in addressing this challenge with innovative solutions for distributed training.
One of our key focuses has been improving communication efficiency in distributed training for graph neural networks (GNNs). Through a mix of deep theoretical research and thorough empirical testing, we’ve developed methods that significantly boost communication efficiency and speed up training convergence. Our work enables seamless training on graphs with up to 100 million nodes, expanding what’s possible in GNN-based learning.
We’re also accelerating distributed training for Transformer models, which are crucial for tasks in both language and vision. Our goal is to push the limits of speed and efficiency in training, helping researchers and practitioners tackle larger and more complex problems in language and image understanding and generation.
At the heart of our efforts is a commitment to advancing distributed training techniques to meet the growing demands of machine learning. Join us as we explore new frontiers, optimize training processes, and drive the evolution of machine learning in a world full of possibilities.
Corresponding Publications: