All Publications
Highlights
Projects
Topics
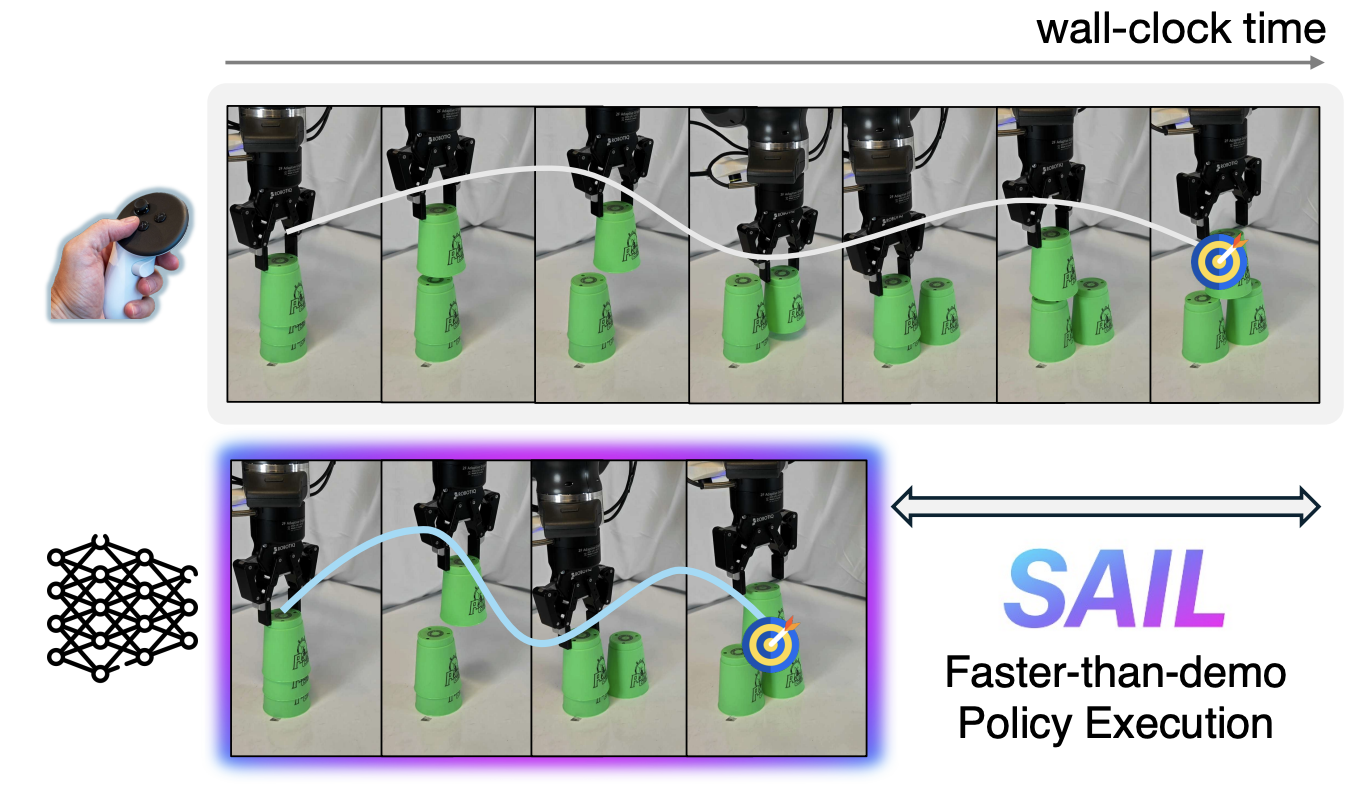
[CoRL 2025] SAIL: Faster-than-Demonstration Execution of Imitation Learning Policies
Nadun Ranawaka Arachchige, Zhenyang Chen, Wonsuhk Jung, Woo Chul Shin, Rohan Bansal, Pierre Barroso, Yu Hang He, Yingyan (Celine) Lin, Benjamin Joffe, Shreyas Kousik, Danfei Xu
[Abstract] [Paper]
Nadun Ranawaka Arachchige, Zhenyang Chen, Wonsuhk Jung, Woo Chul Shin, Rohan Bansal, Pierre Barroso, Yu Hang He, Yingyan (Celine) Lin, Benjamin Joffe, Shreyas Kousik, Danfei Xu
[Abstract] [Paper]
Offline Imitation Learning (IL) methods such as Behavior Cloning are effective at acquiring complex robotic manipulation skills. However, existing IL-trained policies are confined to executing the task at the same speed as shown in demonstration data. This limits the task throughput of a robotic system, a critical requirement for applications such as industrial automation. In this paper, we introduce and formalize the novel problem of enabling faster-than-demonstration execution of visuomotor policies and identify fundamental challenges in robot dynamics and state-action distribution shifts. We instantiate the key insights as SAIL (Speed Adaptation for Imitation Learning), a full-stack system integrating four tightly-connected components: (1) a consistency-preserving action inference algorithm for smooth motion at high speed, (2) high-fidelity tracking of controller-invariant motion targets, (3) adaptive speed modulation that dynamically adjusts execution speed based on motion complexity, and (4) action scheduling to handle real-world system latencies. Experiments on 12 tasks across simulation and two real, distinct robot platforms show that SAIL achieves up to a 4x speedup over demonstration speed in simulation and up to 3.2x speedup in the real world.
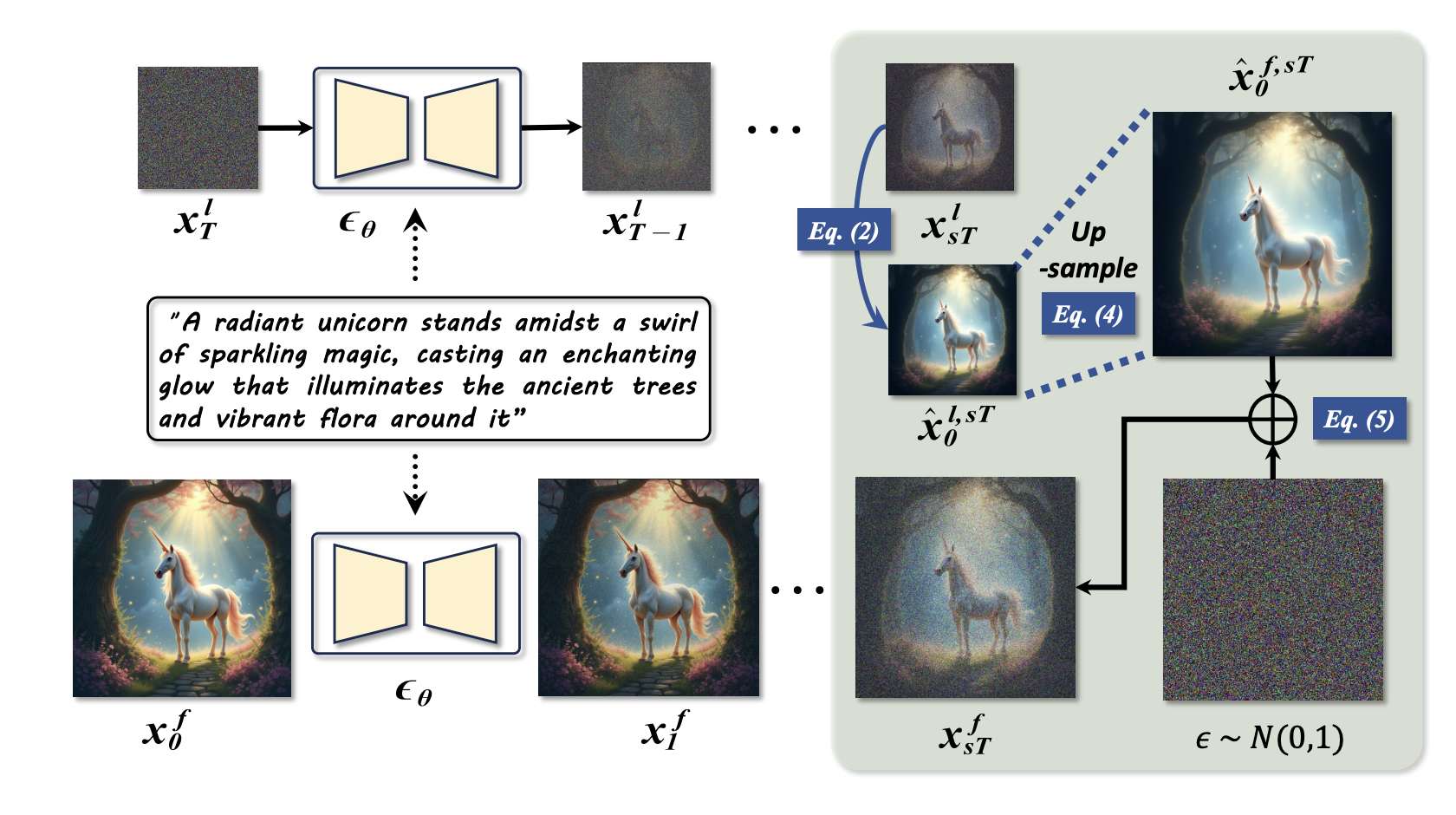
[ICCV 2025] Fewer Denoising Steps or Cheaper Per-Step Inference: Towards Compute-Optimal Diffusion Model Deployment
Zhenbang Du, Yonggan Fu, Lifu Wang, Jiayi Qian, Xiao Luo, Yingyan (Celine) Lin
[Abstract] [Paper]
Zhenbang Du, Yonggan Fu, Lifu Wang, Jiayi Qian, Xiao Luo, Yingyan (Celine) Lin
[Abstract] [Paper]
Diffusion models have shown remarkable success across generative tasks, yet their high computational demands challenge deployment on resource-limited platforms. This paper investigates a critical question for compute-optimal diffusion model deployment: Under a post-training setting without fine-tuning, is it more effective to reduce the number of denoising steps or to use a cheaper per-step inference? Intuitively, reducing the number of denoising steps increases the variability of the distributions across steps, making the model more sensitive to compression. In contrast, keeping more denoising steps makes the differences smaller, preserving redundancy, and making post-training compression more feasible. To systematically examine this, we propose PostDiff, a training-free framework for accelerating pre-trained diffusion models by reducing redundancy at both the input level and module level in a post-training manner. At the input level, we propose a mixed-resolution denoising scheme based on the insight that reducing generation resolution in early denoising steps can enhance low-frequency components and improve final generation fidelity. At the module level, we employ a hybrid module caching strategy to reuse computations across denoising steps. Extensive experiments and ablation studies demonstrate that (1) PostDiff can significantly improve the fidelity-efficiency trade-off of state-of-the-art diffusion models, and (2) to boost efficiency while maintaining decent generation fidelity, reducing per-step inference cost is often more effective than reducing the number of denoising steps.
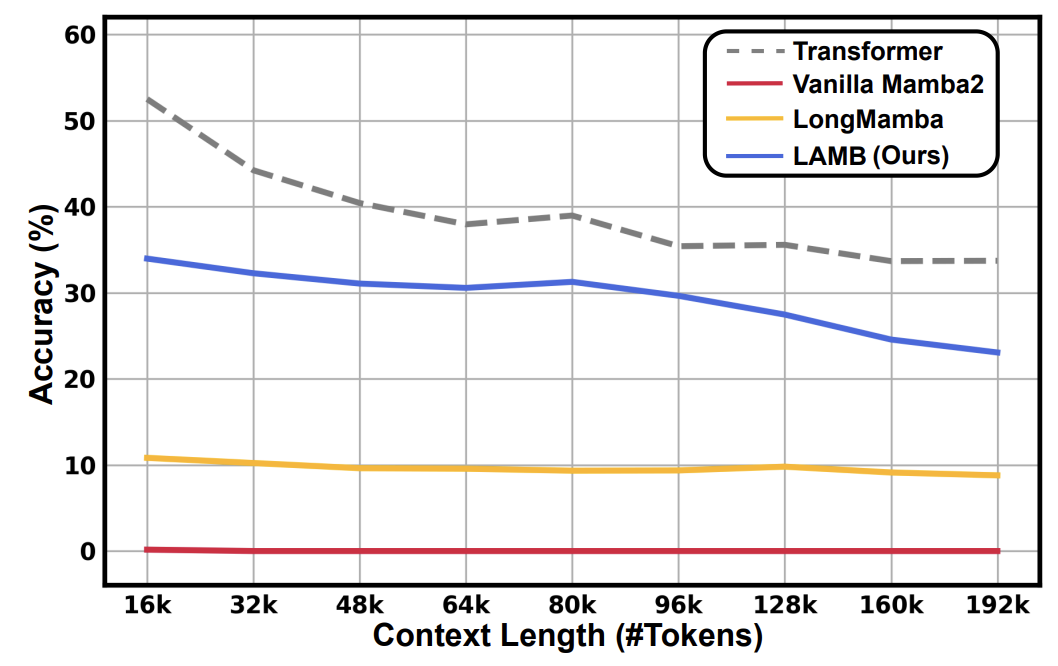
[ACL 2025] LAMB: A Training-Free Method to Enhance the Long-Context Understanding of SSMs via Attention-Guided Token Filtering
Zhifan Ye, Zheng Wang, Kejing Xia, Jihoon Hong, Leshu Li, Lexington Whalen, Cheng Wan, Yonggan Fu, Yingyan (Celine) Lin, Souvik Kundu
[Abstract] [Paper]
Zhifan Ye, Zheng Wang, Kejing Xia, Jihoon Hong, Leshu Li, Lexington Whalen, Cheng Wan, Yonggan Fu, Yingyan (Celine) Lin, Souvik Kundu
[Abstract] [Paper]
State space models (SSMs) achieve efficient
sub-quadratic compute complexity but often
exhibit significant performance drops as context length increases. Recent work attributes
this deterioration to an exponential decay in
hidden state memory. While token filtering has
emerged as a promising remedy, its underlying
rationale and limitations remain largely nonunderstood. In this paper, we first investigate
the attention patterns of Mamba to shed light
on why token filtering alleviates long-context
degradation. Motivated by these findings,
we propose LAMB, a training-free, attentionguided token filtering strategy designed to preserve critical tokens during inference. LAMB
can boost long-context performance for both
pure SSMs and hybrid models, achieving up to
an average improvement of 30.35% over stateof-the-art techniques on standard long-context
understanding benchmarks. Our analysis and
experiments reveal new insights into the interplay between attention, token selection, and
memory retention, and are thus expected to inspire broader applications of token filtering in
long-sequence modeling.
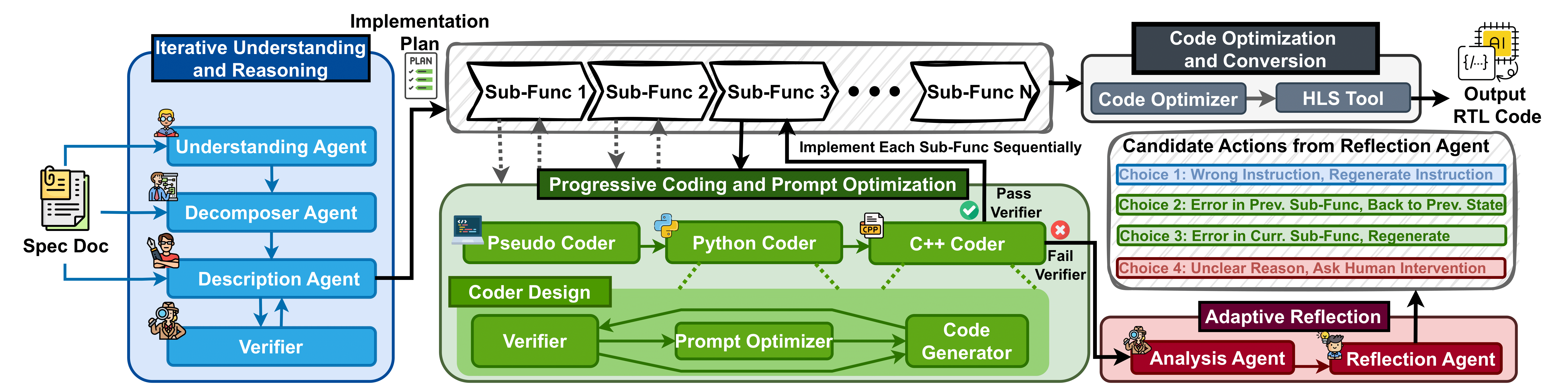
[LAD 2025] Spec2RTL-Agent: Automated Hardware Code Generation from Complex Specifications Using LLM Agent Systems
Zhongzhi Yu, Mingjie Liu, Michael Zimmer, Yingyan (Celine) Lin, Yong Liu, Haoxing Ren
[Abstract] [Paper]
Zhongzhi Yu, Mingjie Liu, Michael Zimmer, Yingyan (Celine) Lin, Yong Liu, Haoxing Ren
[Abstract] [Paper]
Despite recent progress in generating hardware RTL code with LLMs, existing solutions still suffer from a substantial gap between practical application scenarios and the requirements of real-world RTL code development. Prior approaches either focus on overly simplified hardware descriptions or depend on extensive human guidance to process complex specifications, limiting their scalability and automation potential. In this paper, we address this gap by proposing an LLM agent system, termed Spec2RTL-Agent, designed to directly process complex specification documentation and generate corresponding RTL code implementations, advancing LLM-based RTL code generation toward more realistic application settings. To achieve this goal, Spec2RTL-Agent introduces a novel multi-agent collaboration framework that integrates three key enablers: (1) a reasoning and understanding module that translates specifications into structured, step-by-step implementation plans; (2) a progressive coding and prompt optimization module that iteratively refines the code across multiple representations to enhance correctness and synthesisability for RTL conversion; and (3) an adaptive reflection module that identifies and traces the source of errors during generation, ensuring a more robust code generation flow. Instead of directly generating RTL from natural language, our system strategically generates synthesizable C++ code, which is then optimized for HLS. This agent-driven refinement ensures greater correctness and compatibility compared to naive direct RTL generation approaches. We evaluate Spec2RTL-Agent on three specification documents, showing it generates accurate RTL code with up to 75% fewer human interventions than existing methods. This highlights its role as the first fully automated multi-agent system for RTL generation from unstructured specs, reducing reliance on human effort in hardware design.
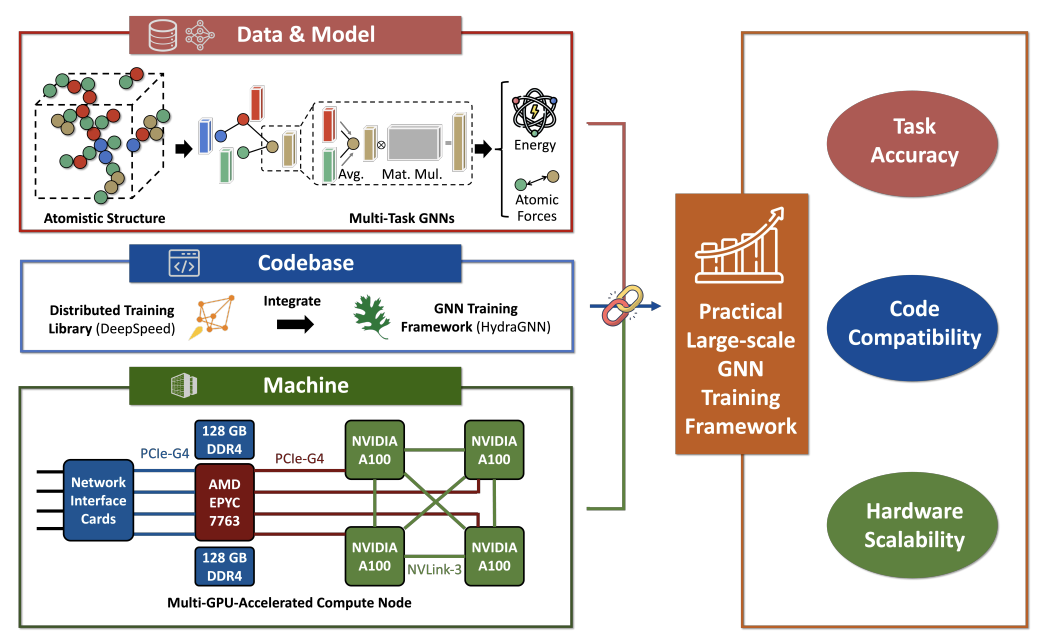
[DAC 2025] Scaling Laws of Graph Neural Networks for Atomistic Materials Modeling
Chaojian Li, Zhifan Ye, Massimiliano Lupo Pasini, Jong Youl Choi, Cheng Wan, Yingyan (Celine) Lin, Prasanna Balaprakash
[Abstract] [Paper]
Chaojian Li, Zhifan Ye, Massimiliano Lupo Pasini, Jong Youl Choi, Cheng Wan, Yingyan (Celine) Lin, Prasanna Balaprakash
[Abstract] [Paper]
Atomistic materials modeling is a critical task with wide-ranging applications, from drug discovery to materials science, where accurate predictions of the target material property can lead to significant advancements in scientific discovery. Graph Neural Networks (GNNs) represent the state-of-the-art approach for modeling atomistic material data thanks to their capacity to capture complex relational structures. While machine learning performance has historically improved with larger models and datasets, GNNs for atomistic materials modeling remain relatively small compared to large language models (LLMs), which leverage billions of parameters and terabyte-scale datasets to achieve remarkable performance in their respective domains. To address this gap, we explore the scaling limits of GNNs for atomistic materials modeling by developing a foundational model with billions of parameters, trained on extensive datasets in terabyte-scale. Our approach incorporates techniques from LLM libraries to efficiently manage large-scale data and models, enabling both effective training and deployment of these large-scale GNN models. This work addresses three fundamental questions in scaling GNNs: the potential for scaling GNN model architectures, the effect of dataset size on model accuracy, and the applicability of LLM-inspired techniques to GNN architectures. Specifically, the outcomes of this study include (1) insights into the scaling laws for GNNs, highlighting the relationship between model size, dataset volume, and accuracy, (2) a foundational GNN model optimized for atomistic materials modeling, and (3) a GNN codebase enhanced with advanced LLM-based training techniques. Our findings lay the groundwork for large-scale GNNs with billions of parameters and terabyte-scale datasets, establishing a scalable pathway for future advancements in atomistic materials modeling.
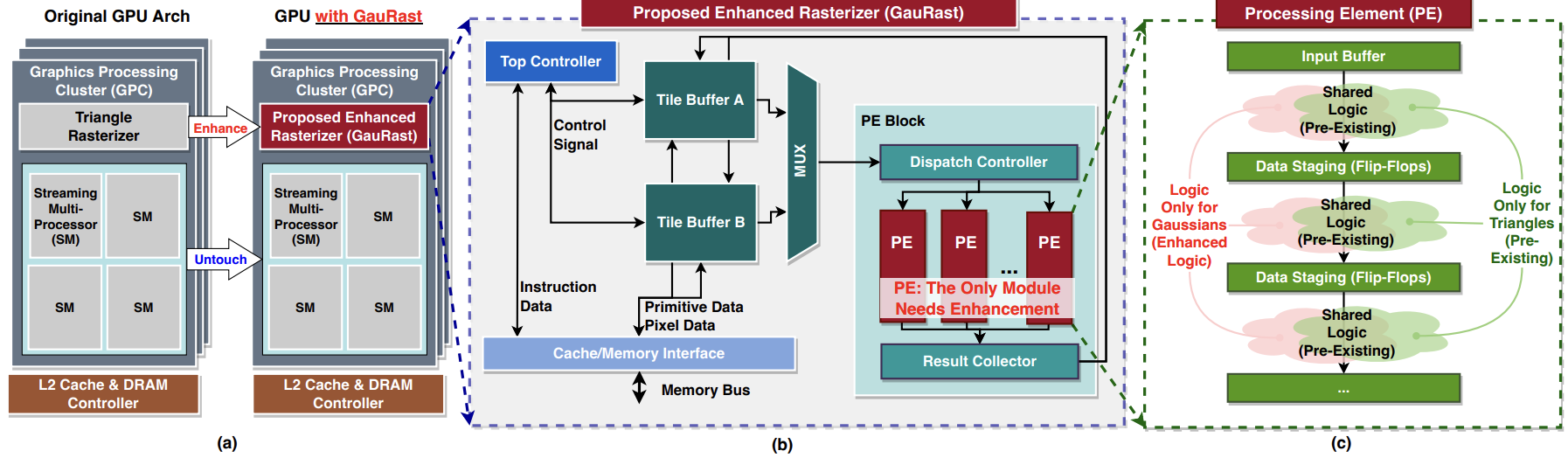
[DAC 2025] GauRast: Enhancing GPU Triangle Rasterizers to Accelerate 3D Gaussian Splatting
Sixu Li, Ben Keller, Yingyan (Celine) Lin, Brucek Khailany
[Abstract] [Paper]
Sixu Li, Ben Keller, Yingyan (Celine) Lin, Brucek Khailany
[Abstract] [Paper]
3D intelligence leverages rich 3D features and stands as a promising frontier in AI, with 3D rendering fundamental to many downstream applications. 3D Gaussian Splatting (3DGS), an emerging high-quality 3D rendering method, requires significant computation, making real-time execution on existing GPU-equipped edge devices infeasible. Previous efforts to accelerate 3DGS rely on dedicated accelerators that require substantial integration overhead and hardware costs. This work proposes an acceleration strategy that leverages the similarities between the 3DGS pipeline and the highly optimized conventional graphics pipeline in modern GPUs. Instead of developing a dedicated accelerator, we enhance existing GPU rasterizer hardware to efficiently support 3DGS operations. Our results demonstrate a 23× increase in processing speed and a 24× reduction in energy consumption, with improvements yielding 6× faster end-to-end runtime for the original 3DGS algorithm and 4× for the latest efficiency-improved pipeline, achieving 24 FPS and 46 FPS respectively. These enhancements incur only a minimal area overhead of 0.2% relative to the entire SoC chip area, underscoring the practicality and efficiency of our approach for enabling 3DGS rendering on resource-constrained platforms.
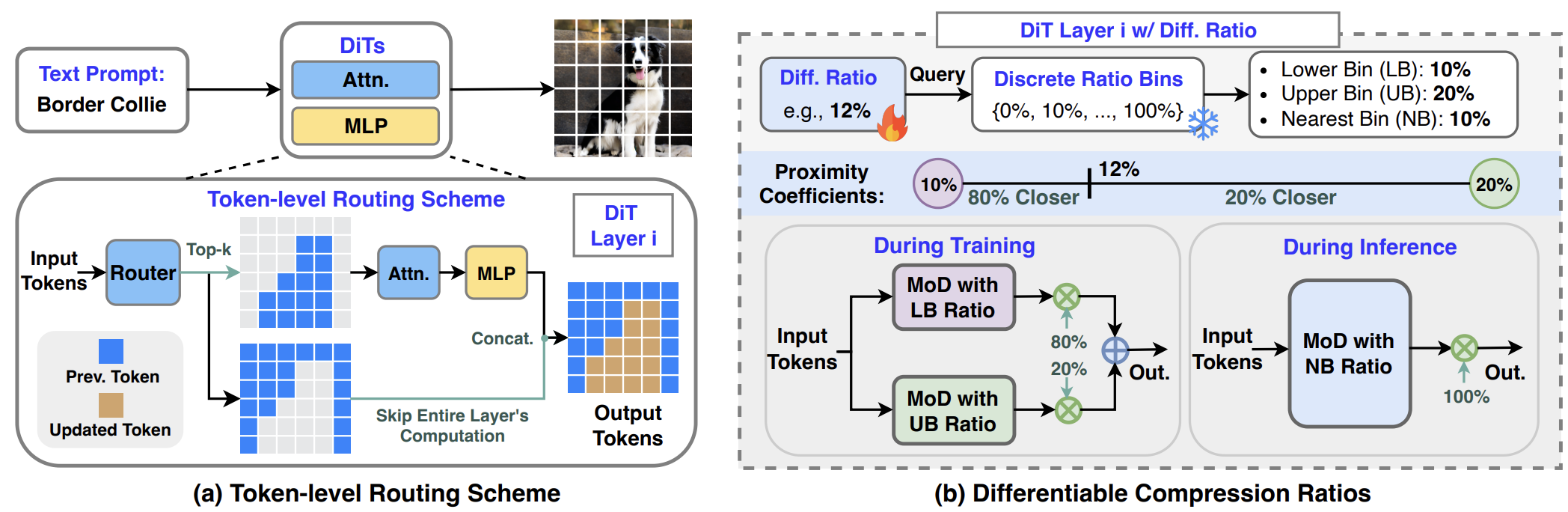
[CVPR 2025] Layer- and Timestep-Adaptive Differentiable Token Compression Ratios for Efficient Diffusion Transformers
Haoran You, Connelly Barnes, Yuqian Zhou, Yan Kang, Zhenbang Du, Wei Zhou, Lingzhi Zhang, Yotam Nitzan, Xiaoyang Liu, Zhe Lin, Eli Shechtman, Sohrab Amirghodsi, Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Project Page ]
Haoran You, Connelly Barnes, Yuqian Zhou, Yan Kang, Zhenbang Du, Wei Zhou, Lingzhi Zhang, Yotam Nitzan, Xiaoyang Liu, Zhe Lin, Eli Shechtman, Sohrab Amirghodsi, Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Project Page ]
Diffusion Transformers (DiTs) have achieved state-of-the-art (SOTA) image generation quality but suffer from high latency and memory inefficiency, making them difficult to deploy on resource-constrained devices. One major efficiency bottleneck is that existing DiTs apply equal computation across all regions of an image. However, not all image tokens are equally important, and certain localized areas require more computation, such as objects. To address this, we propose DiffCR, a dynamic DiT inference framework with differentiable compression ratios, which automatically learns to dynamically route computation across layers and timesteps for each image token, resulting in efficient DiTs. Specifically, DiffCR integrates three features: (1) A token-level routing scheme where each DiT layer includes a router that is fine-tuned jointly with model weights to predict token importance scores. In this way, unimportant tokens bypass the entire layer's computation; (2) A layer-wise differentiable ratio mechanism where different DiT layers automatically learn varying compression ratios from a zero initialization, resulting in large compression ratios in redundant layers while others remain less compressed or even uncompressed; (3) A timestep-wise differentiable ratio mechanism where each denoising timestep learns its own compression ratio. The resulting pattern shows higher ratios for noisier timesteps and lower ratios as the image becomes clearer. Extensive experiments on text-to-image and inpainting tasks show that DiffCR effectively captures dynamism across token, layer, and timestep axes, achieving superior trade-offs between generation quality and efficiency compared to prior works.
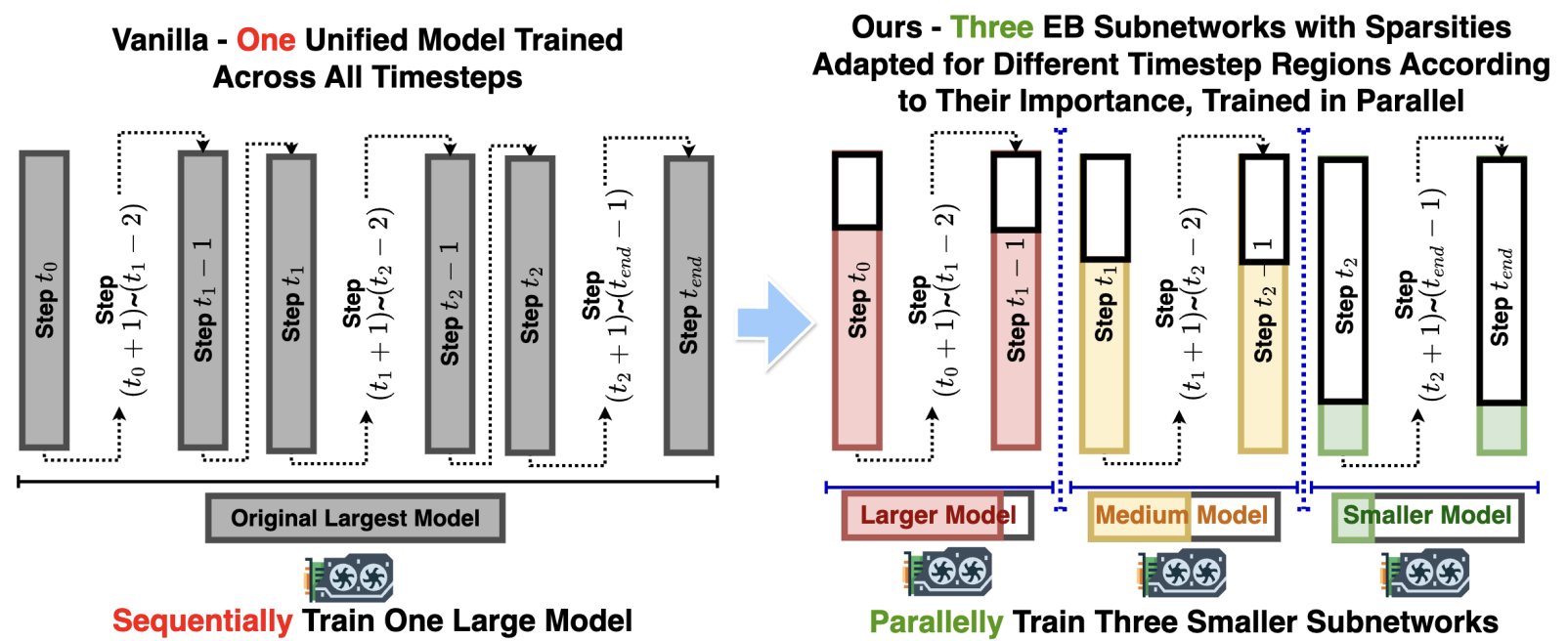
[CVPR 2025] Early-Bird Diffusion: Investigating and Leveraging Timestep-Aware Early-Bird Tickets in Diffusion Models for Efficient Training
Lexington Whalen, Zhenbang Du, Haoran You, Chaojian Li, Sixu Li, Yingyan (Celine) Lin
[Abstract] [Paper] [Code]
Lexington Whalen, Zhenbang Du, Haoran You, Chaojian Li, Sixu Li, Yingyan (Celine) Lin
[Abstract] [Paper] [Code]
Training diffusion models (DMs) requires substantial computational resources due to multiple forward and backward passes across numerous timesteps, motivating research into efficient training techniques. In this paper, we propose EB-Diff-Train, a new efficient DM training approach that is orthogonal to other methods of accelerating DM training, by investigating and leveraging Early-Bird (EB) tickets -- sparse subnetworks that manifest early in the training process and maintain high generation quality. We first investigate the existence of traditional EB tickets in DMs, enabling competitive generation quality without fully training a dense model. Then, we delve into the concept of diffusion-dedicated EB tickets, drawing on insights from varying importance of different timestep regions. These tickets adapt their sparsity levels according to the importance of corresponding timestep regions, allowing for aggressive sparsity during non-critical regions while conserving computational resources for crucial timestep regions. Building on this, we develop an efficient DM training technique that derives timestep-aware EB tickets, trains them in parallel, and combines them during inference for image generation. Extensive experiments validate the existence of both traditional and timestep-aware EB tickets, as well as the effectiveness of our proposed EB-Diff-Train method. This approach can significantly reduce training time both spatially and temporally -- achieving 2.9× to 5.8× speedups over training unpruned dense models, and up to 10.3× faster training compared to standard train-prune-finetune pipelines -- without compromising generative quality.
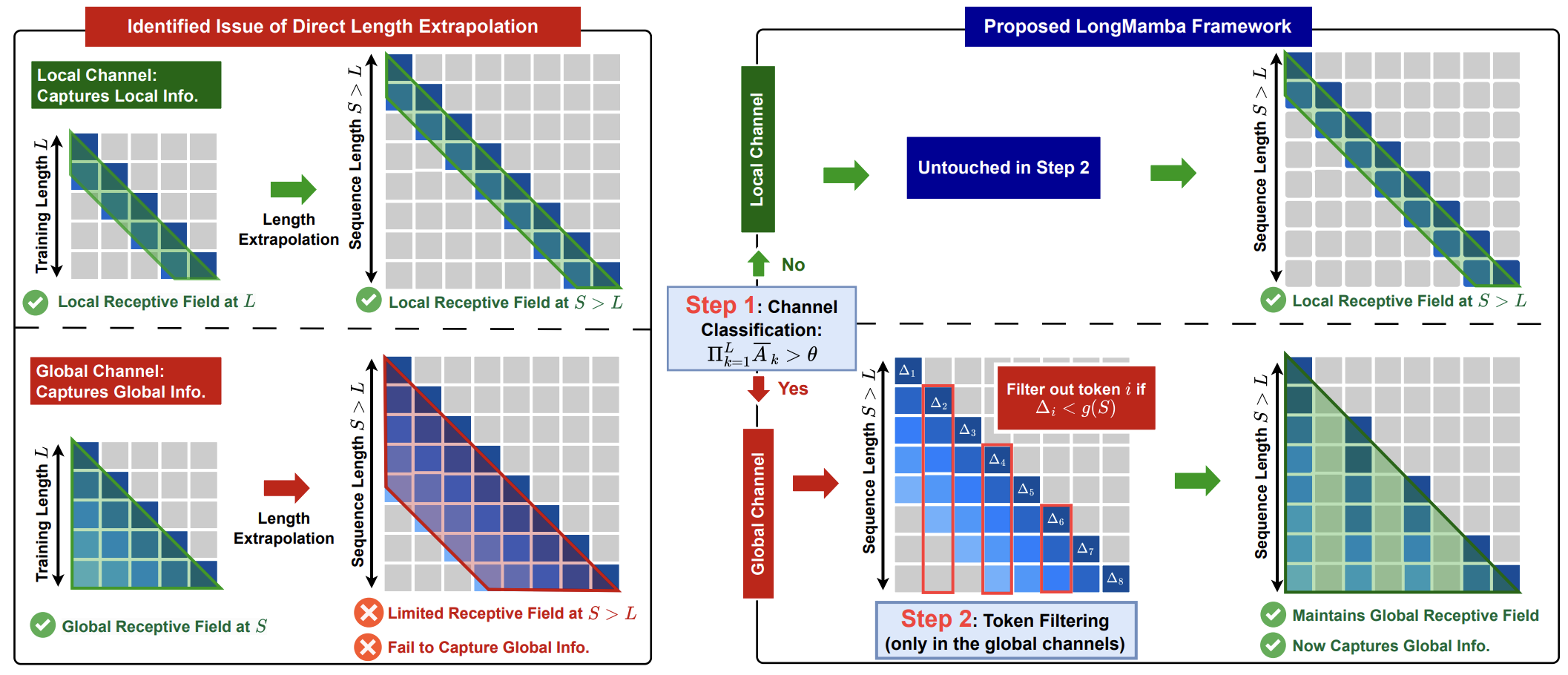
[ICLR 2025] LongMamba: Enhancing Mamba's Long-Context Capabilities via Training-Free Receptive Field Enlargement
Zhifan Ye, Kejing Xia, Yonggan Fu, Xin Dong, Jihoon Hong, Xiangchi Yuan, Shizhe Diao, Jan Kautz, Pavlo Molchanov, Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Project Page ]
Zhifan Ye, Kejing Xia, Yonggan Fu, Xin Dong, Jihoon Hong, Xiangchi Yuan, Shizhe Diao, Jan Kautz, Pavlo Molchanov, Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Project Page ]
State space models (SSMs) have emerged as an efficient alternative to Transformer models for language modeling, offering linear computational complexity and constant memory usage as context length increases. However, despite their efficiency in handling long contexts, recent studies have shown that SSMs, such as Mamba models, generally underperform compared to Transformers in long-context understanding tasks. To address this significant shortfall and achieve both efficient and accurate long-context understanding, we propose LongMamba, a training-free technique that significantly enhances the long-context capabilities of Mamba models. LongMamba builds on our discovery that the hidden channels in Mamba can be categorized into local and global channels based on their receptive field lengths, with global channels primarily responsible for long-context capability. These global channels can become the key bottleneck as the input context lengthens. Specifically, when input lengths largely exceed the training sequence length, global channels exhibit limitations in adaptively extend their receptive fields, leading to Mamba's poor long-context performance. The key idea of LongMamba is to mitigate the hidden state memory decay in these global channels by preventing the accumulation of unimportant tokens in their memory. This is achieved by first identifying critical tokens in the global channels and then applying token filtering to accumulate only those critical tokens. Through extensive benchmarking across synthetic and real-world long-context scenarios, LongMamba sets a new standard for Mamba's long-context performance, significantly extending its operational range without requiring additional training.
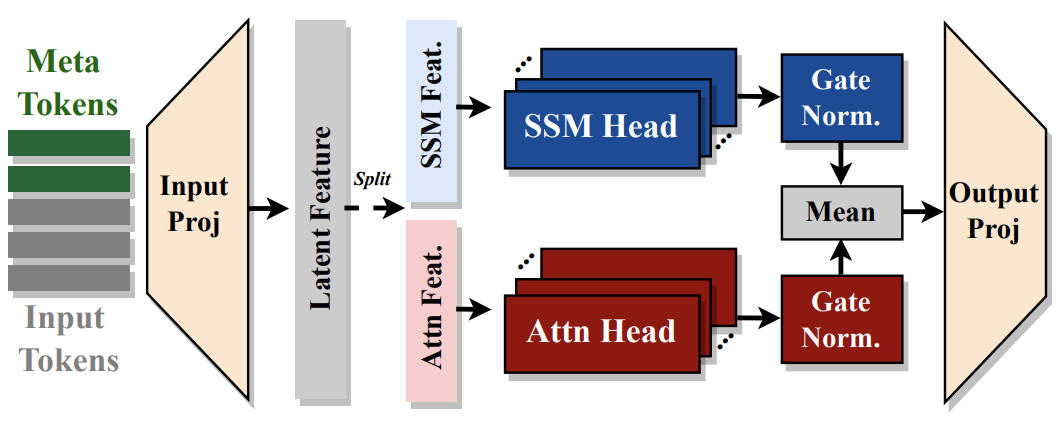
[ICLR 2025] Hymba: A Hybrid-head Architecture for Small Language Models
Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zijia Chen, Ameya Sunil, Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, Yingyan (Celine) Lin, Jan Kautz, Pavlo Molchanov
[Abstract] [Paper] [Code]
Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zijia Chen, Ameya Sunil, Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, Yingyan (Celine) Lin, Jan Kautz, Pavlo Molchanov
[Abstract] [Paper] [Code]
We propose Hymba, a family of small language models featuring a hybrid-head parallel architecture that integrates transformer attention mechanisms with state space models (SSMs) for enhanced efficiency. Attention heads provide high-resolution recall, while SSM heads enable efficient context summarization. Additionally, we introduce learnable meta tokens that are prepended to prompts, storing critical information and alleviating the “forced-to-attend” burden associated with attention mechanisms. This model is further optimized by incorporating cross-layer key-value (KV) sharing and partial sliding window attention, resulting in a compact cache size. During development, we conducted a controlled study comparing various architectures under identical settings and observed significant advantages of our proposed architecture. Notably, Hymba achieves state-of-the-art results for small LMs: Our Hymba-1.5B-Base model surpasses all sub-2B public models in performance and even outperforms Llama-3.2-3B with 1.32% higher average accuracy, an 11.67× cache size reduction, and 3.49× throughput.
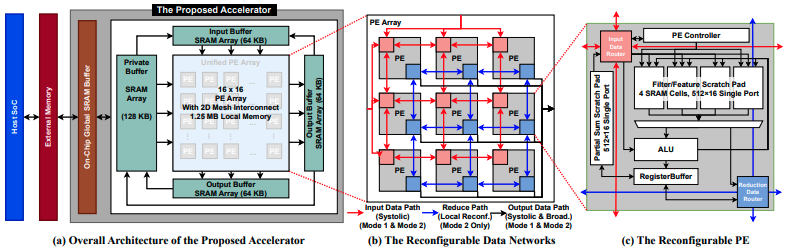
Recent advancements in neural rendering technologies and their supporting devices have paved the way for immersive 3D experiences, significantly transforming human interaction with intelligent devices across diverse applications. However, achieving the desired real-time rendering speeds for immersive interactions is still hindered by (1) the lack of a universal algorithmic solution for different application scenarios and (2) the dedication of existing devices or accelerators to merely specific rendering pipelines. To overcome this challenge, we have developed a unified neural rendering accelerator that caters to a wide array of typical neural rendering pipelines, enabling real-time and on-device rendering across different applications while maintaining both efficiency and compatibility. Our accelerator design is based on the insight that, although neural rendering pipelines vary and their algorithm designs are continually evolving, they typically share common operators, predominantly executing similar workloads. Building on this insight, we propose a reconfigurable hardware architecture that can dynamically adjust dataflow to align with specific rendering metric requirements for diverse applications, effectively supporting both typical and the latest hybrid rendering pipelines. Benchmarking experiments and ablation studies on both synthetic and real-world scenes demonstrate the effectiveness of the proposed accelerator. The proposed unified accelerator stands out as the first solution capable of achieving real-time neural rendering across varied representative pipelines on edge devices, potentially paving the way for the next generation of neural graphics applications.
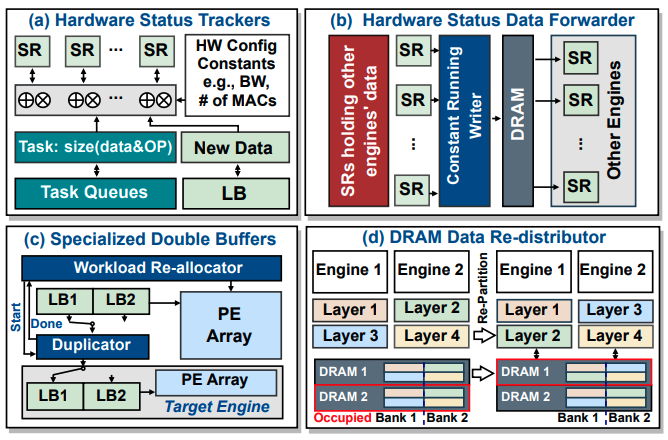
Real-time Codec Avatars, which employ deep generative models for 3D reconstruction of human features, are crucial for immersive telepresence in AR/VR environments. However, deploying these avatars in real-time on AR/VR headsets is challenging due to the inability of existing devices to achieve satisfying performance within stringent hardware resource constraints. To address these challenges, we introduce Re-CATA, an innovative full-stack and flexible Codec Avatar accelerator design framework. Re-CATA is designed to deliver real-time throughput (greater than 120 FPS) for the complete Codec Avatar processing pipeline within an edge-level power budget of 5 W under FPGA prototyping. Our approach begins by abstracting the operation mapping and scheduling challenges inherent in Codec Avatars, which require both centralized and distributed processing to handle dynamically changing workloads. We propose a novel hardware resource and workload partitioning scheme optimized for these fluctuating demands. To complement this, we introduce an agile runtime scheduling system for efficient workload reallocation among computing units as needed, recognizing the limitations of static partitioning in rapidly evolving workload scenarios. Furthermore, our micro-architecture design incorporates unified computing modules and efficient hardware peripherals, enabling seamless workload balancing across the Codec Avatar processing pipeline. We evaluate the Re-CATA accelerators via on-board FPGA prototyping, comparing them to various baselines, including commercial AR/VR SoCs and academic accelerators. This evaluation demonstrates a maximum speedup of up to 5.95× under similar settings.
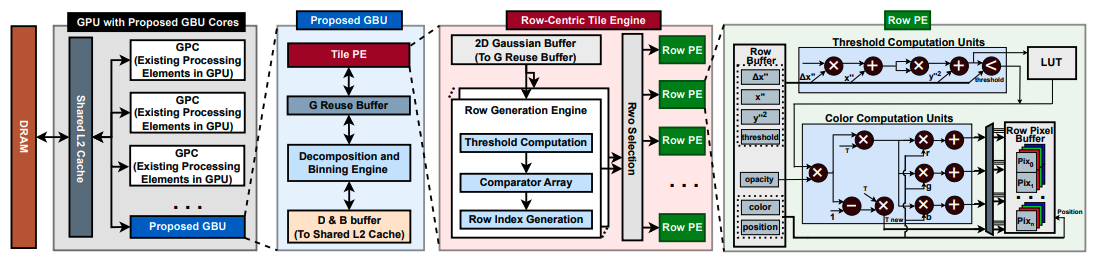
The rapidly advancing field of Augmented and Virtual Reality (AR/VR) demands real-time, photorealistic rendering on resource-constrained platforms. 3D Gaussian Splatting, delivering state-of-the-art (SOTA) performance in rendering efficiency and quality, has emerged as a promising solution across a broad spectrum of AR/VR applications. However, despite its effectiveness on high-end GPUs, it struggles on edge systems like the Jetson Orin NX Edge GPU, achieving only 7-17 FPS -- well below the over 60 FPS standard required for truly immersive AR/VR experiences. Addressing this challenge, we perform a comprehensive analysis of Gaussian-based AR/VR applications and identify the Gaussian Blending Stage, which intensively calculates each Gaussian's contribution at every pixel, as the primary bottleneck. In response, we propose a Gaussian Blending Unit (GBU), an edge GPU plug-in module for real-time rendering in AR/VR applications. Notably, our GBU can be seamlessly integrated into conventional edge GPUs and collaboratively supports a wide range of AR/VR applications. Specifically, GBU incorporates an intra-row sequential shading (IRSS) dataflow that shades each row of pixels sequentially from left to right, utilizing a two-step coordinate transformation. When directly deployed on a GPU, the proposed dataflow achieved a non-trivial 1.72x speedup on real-world static scenes, though still falls short of real-time rendering performance. Recognizing the limited compute utilization in the GPU-based implementation, GBU enhances rendering speed with a dedicated rendering engine that balances the workload across rows by aggregating computations from multiple Gaussians. Experiments across representative AR/VR applications demonstrate that our GBU provides a unified solution for on-device real-time rendering while maintaining SOTA rendering quality.
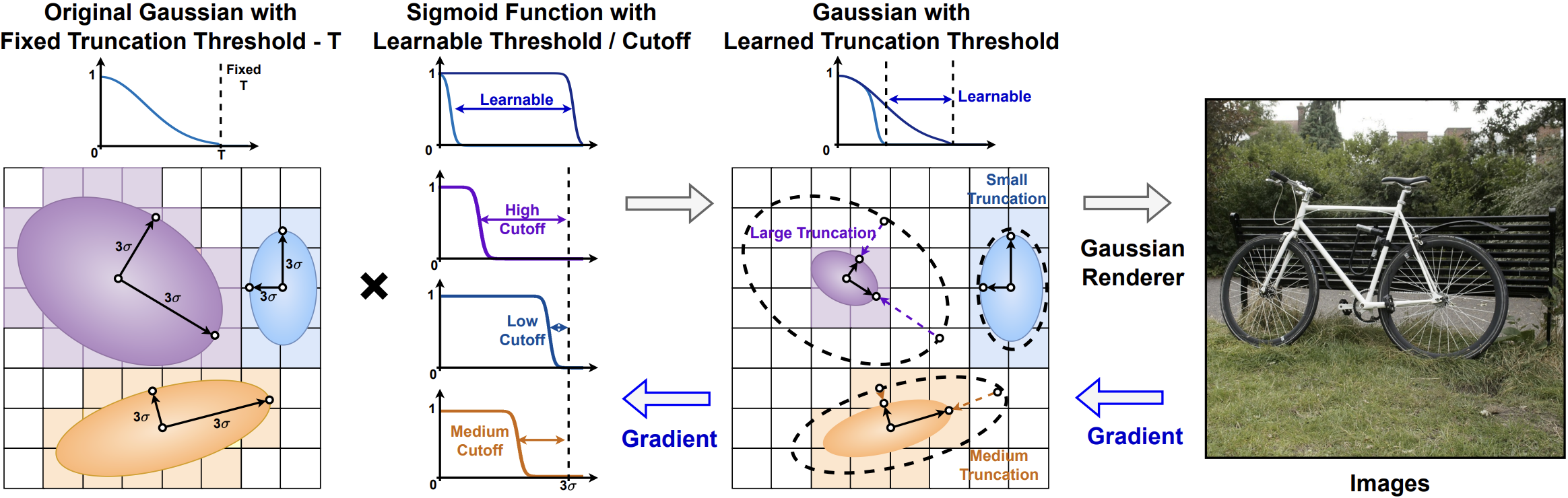
[NeurIPS 2024] 3D Gaussian Rendering Can Be Sparser: Efficient Rendering via Learned Fragment Pruning
Zhifan Ye, Chenxi Wan, Chaojian Li, Jihoon Hong, Sixu Li, Leshu Li, Yongan Zhang, Yingyan (Celine) Lin
[Abstract] [Paper] [Code]
Zhifan Ye, Chenxi Wan, Chaojian Li, Jihoon Hong, Sixu Li, Leshu Li, Yongan Zhang, Yingyan (Celine) Lin
[Abstract] [Paper] [Code]
3D Gaussian splatting has recently emerged as a promising technique for novel view synthesis from sparse image sets, yet comes at the cost of requiring millions of 3D Gaussian primitives to reconstruct each 3D scene. This largely limits its application to resource-constrained devices and applications. Despite advances in Gaussian pruning techniques that aim to remove individual 3D Gaussian primitives, the significant reduction in primitives often fails to translate into commensurate increases in rendering speed, impeding efficiency and practical deployment. We identify that this discrepancy arises due to the overlooked impact of fragment count per Gaussian (i.e., the number of pixels each Gaussian is projected onto). To bridge this gap and meet the growing demands for efficient on-device 3D Gaussian rendering, we propose fragment pruning, an orthogonal enhancement to existing pruning methods that can significantly accelerate rendering by selectively pruning fragments within each Gaussian. Our pruning framework dynamically optimizes the pruning threshold for each Gaussian, markedly improving rendering speed and quality. Extensive experiments in both static and dynamic scenes validate the effectiveness of our approach. For instance, by integrating our fragment pruning technique with state-of-the-art Gaussian pruning methods, we achieve up to a 1.71 speedup on an edge GPU device, the Jetson Orin NX, and enhance rendering quality by an average of 0.16 PSNR on the Tanks&Temples dataset. Our code is available at https://github.com/GATECH-EIC/Fragment-Pruning.
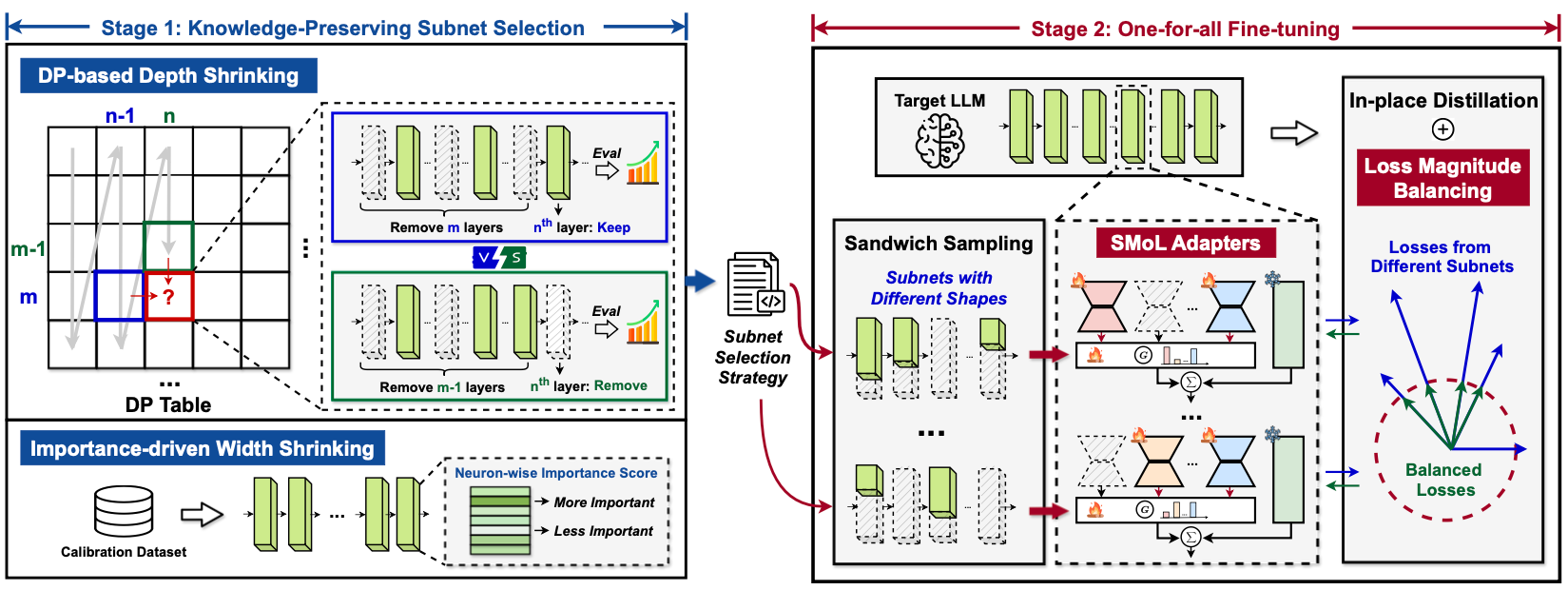
[NeurIPS 2024] AmoebaLLM: Constructing Any-Shape Large Language Models for Efficient and Instant Deployment
Yonggan Fu, Zhongzhi Yu, Junwei Li, Jiayi Qian, Yongan Zhang, Xiangchi Yuan, Dachuan Shi, Roman Yakunin, Yingyan (Celine) Lin
[Abstract] [Paper]
Yonggan Fu, Zhongzhi Yu, Junwei Li, Jiayi Qian, Yongan Zhang, Xiangchi Yuan, Dachuan Shi, Roman Yakunin, Yingyan (Celine) Lin
[Abstract] [Paper]
Motivated by the transformative capabilities of large language models (LLMs) across various natural language tasks, there has been a growing demand to deploy these models effectively across diverse real-world applications and platforms. However, the challenge of efficiently deploying LLMs has become increasingly pronounced due to the varying application-specific performance requirements and the rapid evolution of computational platforms, which feature diverse resource constraints and deployment flows. These varying requirements necessitate LLMs that can adapt their structures (depth and width) for optimal efficiency across different platforms and application specifications. To address this critical gap, we propose AmoebaLLM, a novel framework designed to enable the instant derivation of LLM subnets of arbitrary shapes, which achieve the accuracy-efficiency frontier and can be extracted immediately after a one-time fine-tuning. In this way, AmoebaLLM significantly facilitates rapid deployment tailored to various platforms and applications. Specifically, AmoebaLLM integrates three innovative components: (1) a knowledge-preserving subnet selection strategy that features a dynamic-programming approach for depth shrinking and an importance-driven method for width shrinking; (2) a shape-aware mixture of LoRAs to mitigate gradient conflicts among subnets during fine-tuning; and (3) an in-place distillation scheme with loss-magnitude balancing as the fine-tuning objective. Extensive experiments validate that AmoebaLLM not only sets new standards in LLM adaptability but also successfully delivers subnets that achieve state-of-the-art trade-offs between accuracy and efficiency.
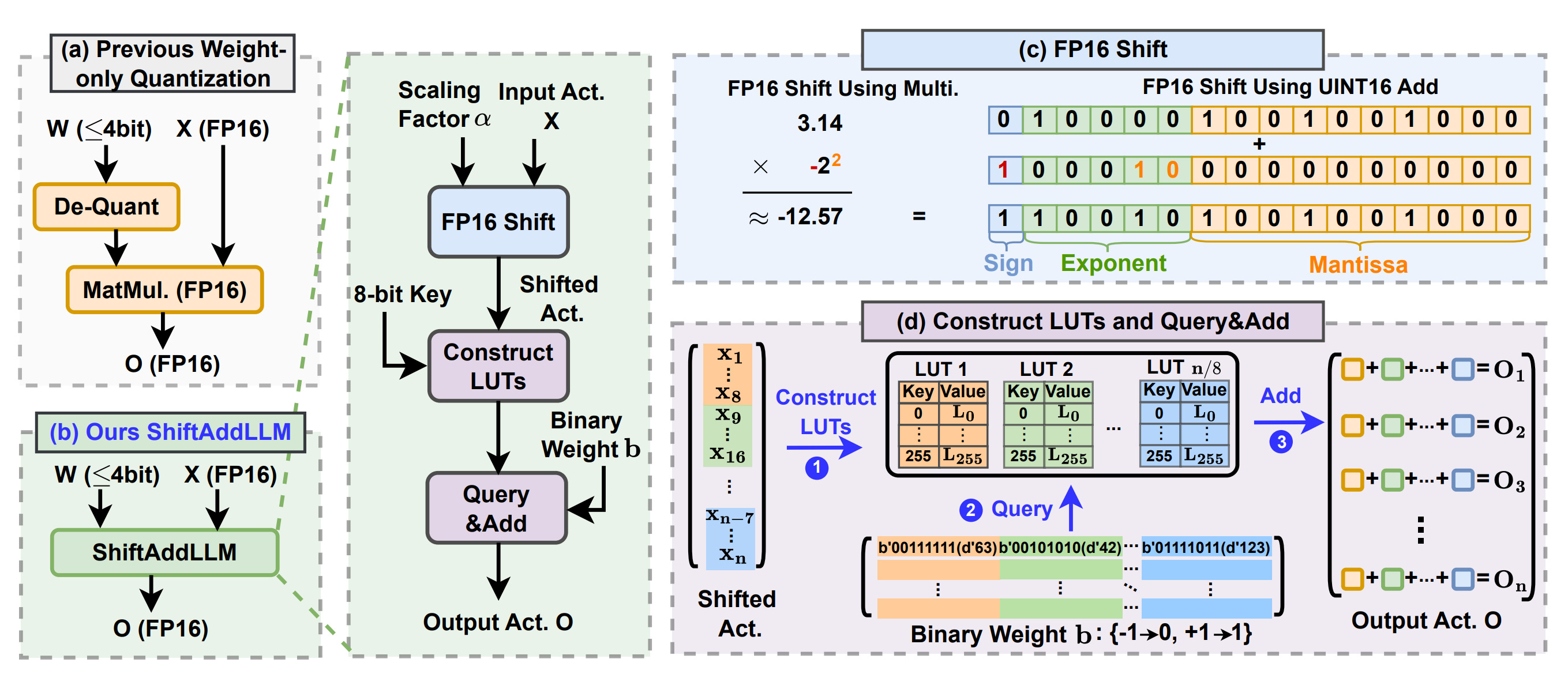
[NeurIPS 2024] ShiftAddLLM: Accelerating Pretrained LLMs via Post-Training Multiplication-Less Reparameterization
Haoran You, Yipin Guo, Yichao Fu, Wei Zhou, Huihong Shi, Xiaofan Zhang, Souvik Kundu, Amir Yazdanbakhsh, Yingyan (Celine) Lin
[Abstract] [Paper]
Haoran You, Yipin Guo, Yichao Fu, Wei Zhou, Huihong Shi, Xiaofan Zhang, Souvik Kundu, Amir Yazdanbakhsh, Yingyan (Celine) Lin
[Abstract] [Paper]
Large language models (LLMs) have shown impressive performance on language tasks but face challenges when deployed on resource-constrained devices due to their extensive parameters and reliance on dense multiplications, resulting in high memory demands and significant latency bottlenecks. Shift and add reparameterization offers a promising solution by replacing costly multiplications with hardware-friendly primitives in both the attention and multi-layer perceptron (MLP) layers of an LLM. However, current reparameterization techniques necessitate training from scratch or full parameter fine-tuning to restore accuracy, which is often resource-intensive for LLMs. To this end, we propose accelerating pretrained LLMs through a post-training shift and add reparameterization to yield efficient multiplication-less LLMs, dubbed ShiftAddLLM . Specifically, we quantize and reparameterize each weight matrix in LLMs into a series of binary matrices and associated scaling factor matrices. Each scaling factor, corresponding to a group of weights, is quantized to powers of two. This reparameterization transforms the original multiplications between weights and activations into two steps: (1) bitwise shifts between activations and scaling factors, and (2) queries and adds these results according to the binary matrices. Further, to reduce the accuracy drop, we present a multi-objective optimization method to minimize both weight and output activation reparameterization errors. Finally, based on the observation of varying sensitivity across layers to reparameterization, we develop an automated bit allocation strategy to further reduce memory usage and latency. Experiments on five LLM families and eight tasks consistently validate the effectiveness of ShiftAddLLM, achieving average perplexity improvements of 5.6 and 22.7 at comparable or even lower latency compared to the most competitive quantized LLMs at 3 and 2 bits, respectively, and more than 80% memory and energy reductions over the original LLMs.
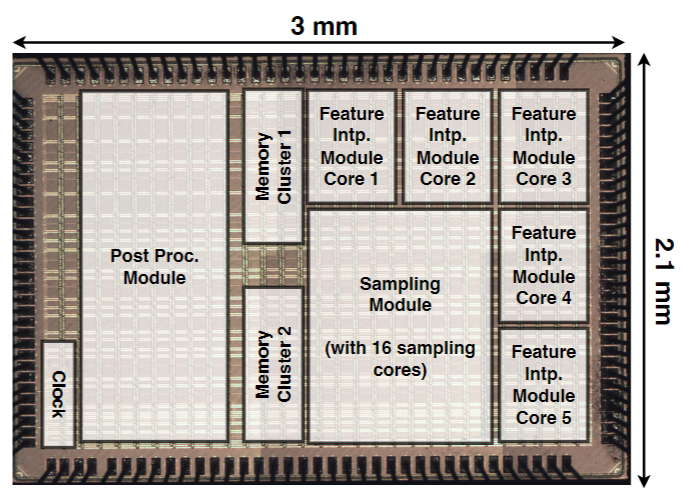
Recent breakthroughs in Neural Radiance Field (NeRF) based 3D reconstruction and rendering have spurred the possibility of immersive experiences in augmented and virtual reality (AR/VR). However, current NeRF acceleration techniques are still inadequate for real-world AR/VR applications due to: 1) the lack of end-to-end pipeline acceleration support, which causes impractical off-chip bandwidth demands for edge devices, and 2) limited scalability in handling large-scale scenes. To tackle these limitations, we have developed an end-to-end, scalable 3D acceleration framework called Fusion-3D, capable of instant scene reconstruction and real-time rendering. Fusion-3D achieves these goals through two key innovations: 1) an optimized end-to-end processor for all three stages of the NeRF pipeline, featuring dynamic scheduling and hardware-aware sampling in the first stage, and a shared, reconfigurable pipeline with mixed-precision arithmetic in the second and third stages; 2) a multi-chip archi-tecture for handling large-scale scenes, integrating a three-level hierarchical tiling scheme that minimizes inter-chip communica-tion and balances workloads across chips. Extensive experiments validate the effectiveness of Fusion-3D in facilitating real-time, energy-efficient 3D reconstruction and rendering. Specifically, we tape out a prototype chip in 28nm CMOS to evaluate the effectiveness of the proposed end-to-end processor. Extensive simulation based on the on-silicon measurements demonstrates a 2.5× and 6× throughput improvement in training and in-ference, respectively, compared to state-of-the-art accelerators. Furthermore, to assess the multi-chip architecture, we integrate four chips into a single PCB as a prototype. Further simulation results show that the multi-chip system achieves a 7.3× and 6.5× throughput improvement in training and inference, respectively, over the Nvidia 2080Ti GPU. To the best of our knowledge, Fusion-3D is the first to achieve both instant (≤ 2 seconds) 3D reconstruction and real-time (≥ 30 FPS) rendering, while only requiring the bandwidth of the most commonly used USB port (0.625 GB/s, 5 Gbps) in edge devices for off-chip communication.
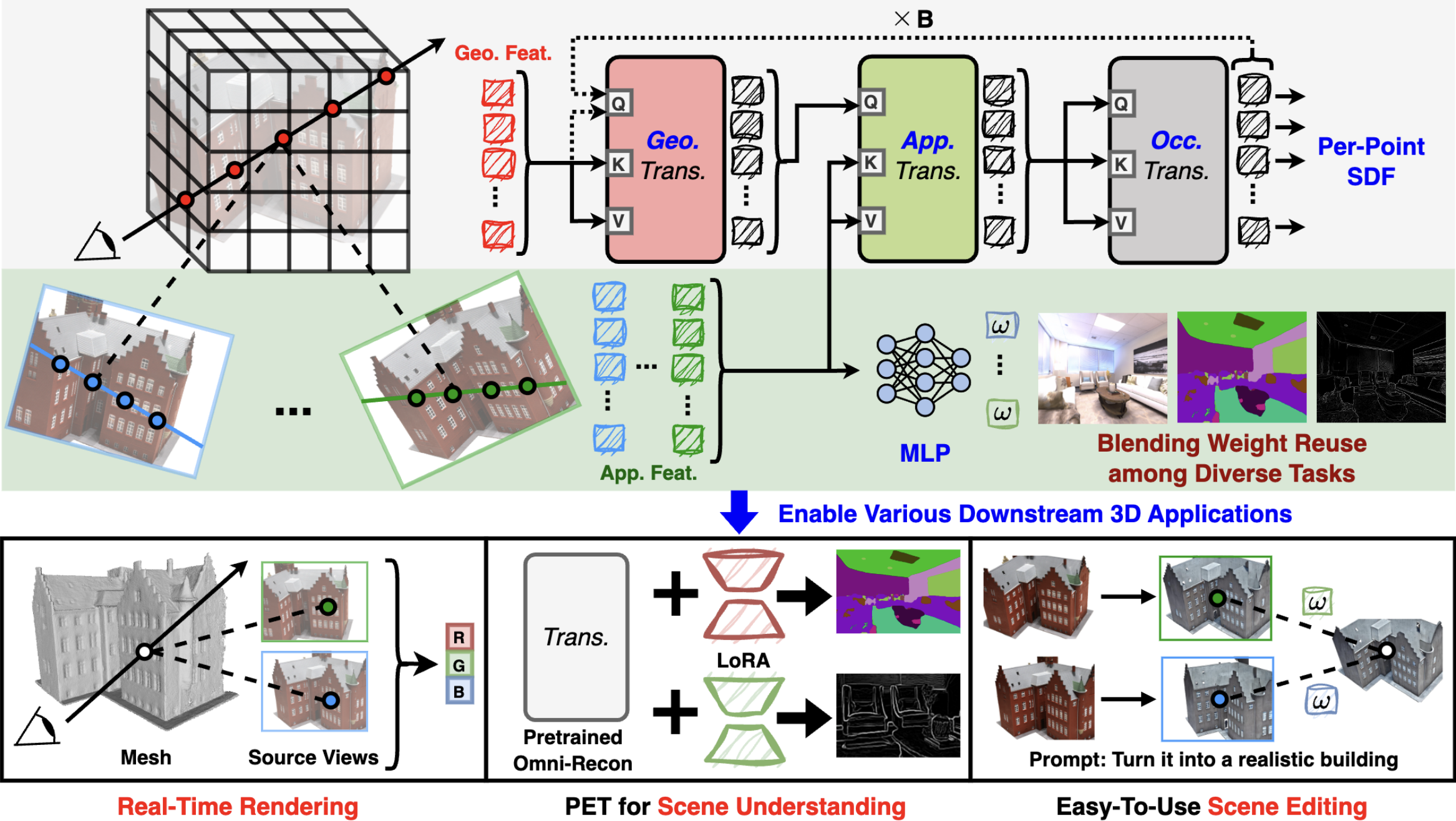
Recent breakthroughs in Neural Radiance Fields (NeRFs) have sparked significant demand for their integration into real-world 3D applications. However, the varied functionalities required by different 3D applications often necessitate diverse NeRF models with various pipelines, leading to tedious NeRF training for each target task and cumbersome trial-and-error experiments. Drawing inspiration from the generalization capability and adaptability of emerging foundation models, our work aims to develop one general-purpose NeRF for handling diverse 3D tasks. We achieve this by proposing a framework called Omni-Recon, which is capable of (1) generalizable 3D reconstruction and zero-shot multitask scene understanding, and (2) adaptability to diverse downstream 3D applications such as real-time rendering and scene editing. Our key insight is that an image-based rendering pipeline, with accurate geometry and appearance estimation, can lift 2D image features into their 3D counterparts, thus extending widely explored 2D tasks to the 3D world in a generalizable manner. Specifically, our Omni-Recon features a general-purpose NeRF model using image-based rendering with two decoupled branches: one complex transformer-based branch that progressively fuses geometry and appearance features for accurate geometry estimation, and one lightweight branch for predicting blending weights of source views. This design achieves state-of-the-art (SOTA) generalizable 3D surface reconstruction quality with blending weights reusable across diverse tasks for zero-shot multitask scene understanding. In addition, it can enable real-time rendering after baking the complex geometry branch into meshes, swift adaptation to achieve SOTA generalizable 3D understanding performance, and seamless integration with 2D diffusion models for text-guided 3D editing.
[TCASAI 2024]
Towards Efficient Neuro-Symbolic AI: From Workload Characterization to Hardware Architecture
Zishen Wan, Che-Kai Liu, Hanchen Yang, Ritik Raj, Chaojian Li, Haoran You, Yonggan Fu, Cheng Wan, Sixu Li, Youbin Kim, Ananda Samajdar, Yingyan (Celine) Lin, Mohamed Ibrahim, Jan M. Rabaey, Tushar Krishna, and Arijit Raychowdhury
[Abstract]
Zishen Wan, Che-Kai Liu, Hanchen Yang, Ritik Raj, Chaojian Li, Haoran You, Yonggan Fu, Cheng Wan, Sixu Li, Youbin Kim, Ananda Samajdar, Yingyan (Celine) Lin, Mohamed Ibrahim, Jan M. Rabaey, Tushar Krishna, and Arijit Raychowdhury
[Abstract]
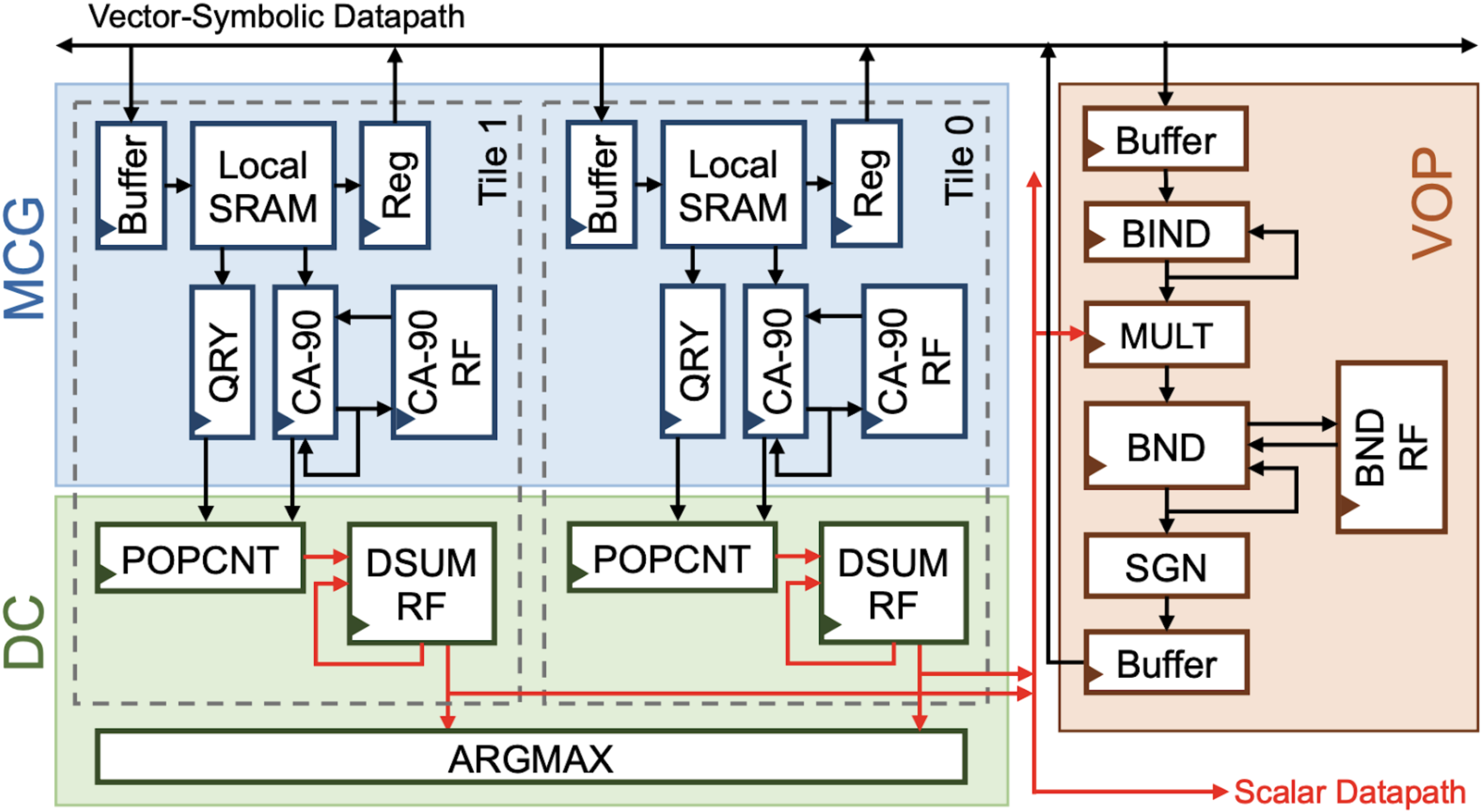
The remarkable advancements in artificial intelligence (AI), primarily driven by deep neural networks, are facing challenges surrounding unsustainable computational trajectories, limited robustness, and a lack of explainability. To develop next-generation cognitive AI systems, neuro-symbolic AI emerges as a promising paradigm, fusing neural and symbolic approaches to enhance interpretability, robustness, and trustworthiness, while facilitating learning from much less data. Recent neuro-symbolic systems have demonstrated great potential in collaborative human-AI scenarios with reasoning and cognitive capabilities. In this paper, we aim to understand the workload characteristics and potential architectures for neuro-symbolic AI. We first systematically categorize neuro-symbolic AI algorithms, and then experimentally evaluate and analyze them in terms of runtime, memory, computational operators, sparsity, and system characteristics on CPUs, GPUs, and edge SoCs. Our studies reveal that neuro-symbolic models suffer from inefficiencies on off-the-shelf hardware, due to the memory-bound nature of vector-symbolic and logical operations, complex flow control, data dependencies, sparsity variations, and limited scalability. Based on profiling insights, we suggest cross-layer optimization solutions and present a hardware acceleration case study for vector-symbolic architecture to improve the performance, efficiency, and scalability of neuro-symbolic computing. Finally, we discuss the challenges and potential future directions of neuro-symbolic AI from both system and architectural perspectives.
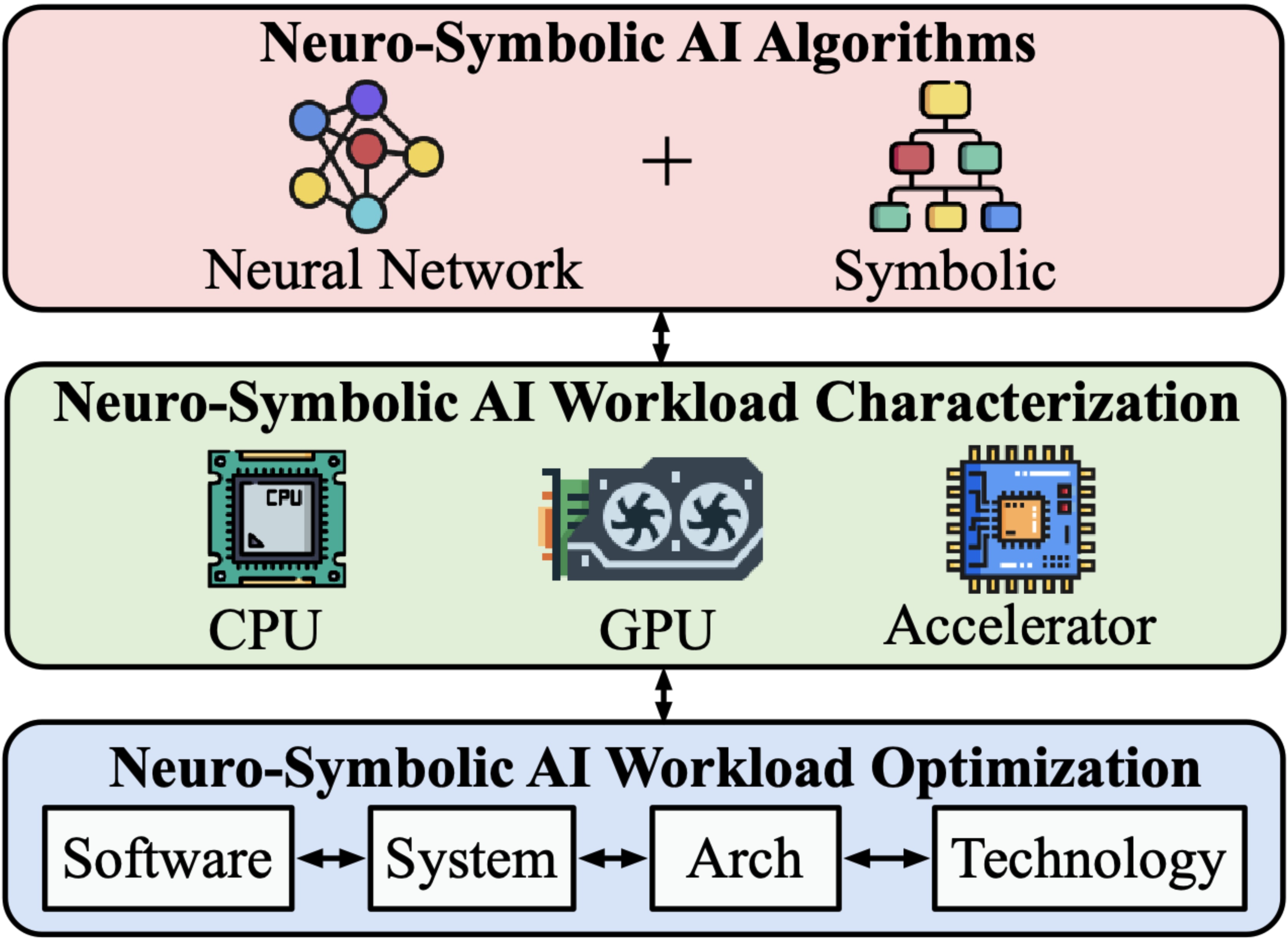
The remarkable advancements in artificial intelligence (AI), primarily driven by deep neural networks, are facing challenges surrounding unsustainable computational trajectories, limited robustness, and a lack of explainability. To develop next-generation cognitive AI systems, neuro-symbolic AI emerges as a promising paradigm, fusing neural and symbolic approaches to enhance interpretability, robustness, and trustworthiness, while facilitating learning from much less data. Recent neuro-symbolic systems have demonstrated great potential in collaborative human-AI scenarios with reasoning and cognitive capabilities. In this paper, we aim to understand the workload characteristics and potential architectures for neuro-symbolic AI. We first systematically categorize neuro-symbolic AI algorithms, and then experimentally evaluate and analyze them in terms of runtime, memory, computational operators, sparsity, and system characteristics on CPUs, GPUs, and edge SoCs. Our studies reveal that neuro-symbolic models suffer from inefficiencies on off-the-shelf hardware, due to the memory-bound nature of vector-symbolic and logical operations, complex flow control, data dependencies, sparsity variations, and limited scalability. Based on profiling insights, we suggest cross-layer optimization solutions to improve the performance, efficiency, and scalability of neuro-symbolic computing. Finally, we discuss the challenges and potential future directions of neuro-symbolic AI from both system and architectural perspectives.
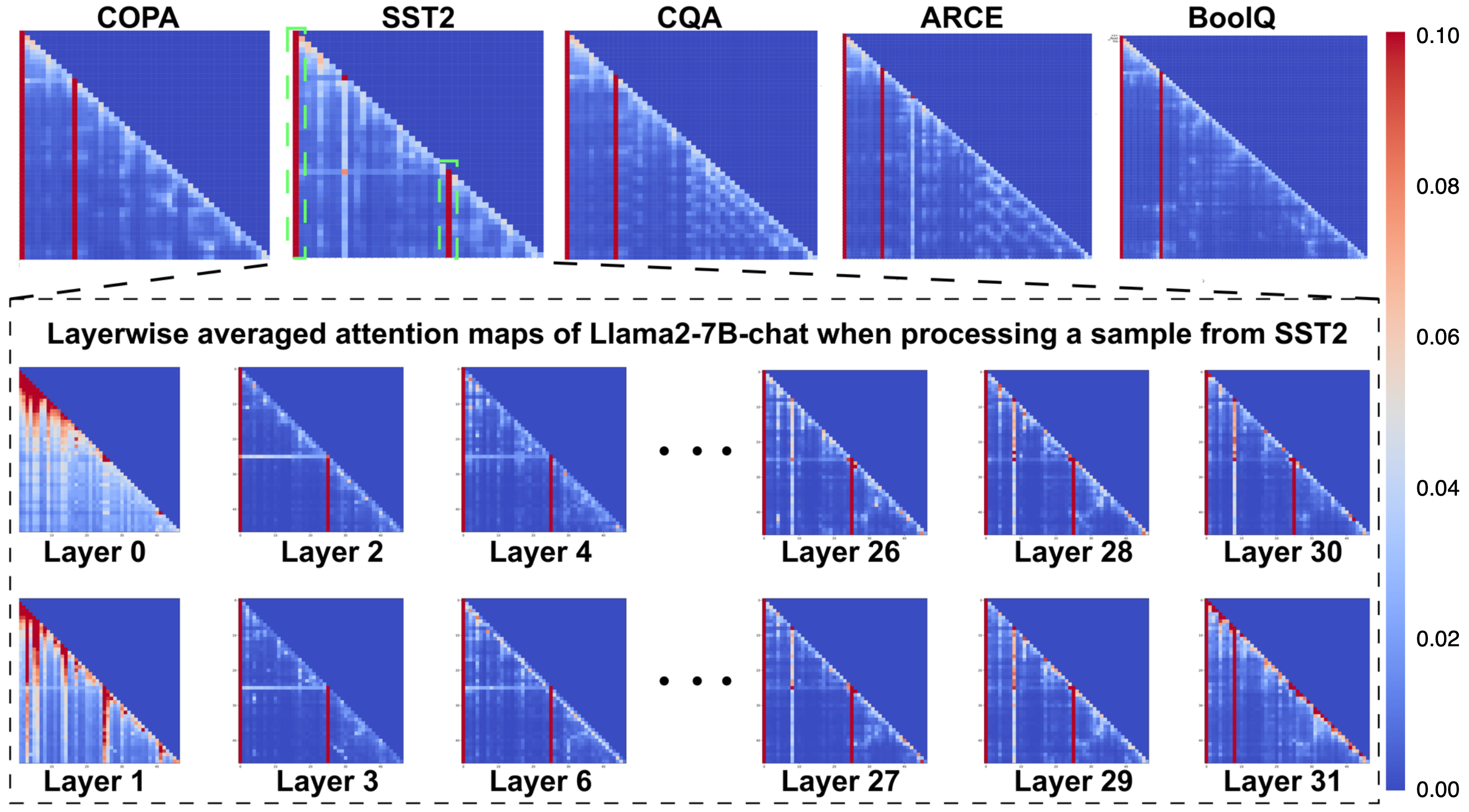
[ICML 2024] Unveiling and Harnessing Hidden Attention Sinks: Enhancing Large Language Models without Training through Attention Calibration
Zhongzhi Yu, Zheng Wang, Yonggan Fu, Shi Huihong, Khalid Shaikh, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Video] [Project Page ]
Zhongzhi Yu, Zheng Wang, Yonggan Fu, Shi Huihong, Khalid Shaikh, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Video] [Project Page ]
Attention is a fundamental component behind the remarkable achievements of large language models (LLMs). However, our current understanding of the attention mechanism, especially in terms of how attention distributions are established, remains limited. Inspired by recent studies that explore the presence of attention sinks in the initial tokens, which receive disproportionately large attention scores despite their lack of semantic importance, this work delves deeper into this phenomenon. We aim to provide a more profound understanding of the existence of attention sinks within LLMs and to uncover ways to enhance LLMs' achievable accuracy by directly optimizing the attention distributions, without the need for weight finetuning. Specifically, this work begins with comprehensive visualizations of the attention distributions in LLMs during inference across various inputs and tasks. Based on these visualizations, for the first time, we discover that (1) attention sinks occur not only at the start of sequences but also within later tokens of the input, and (2) not all attention sinks have a positive impact on the achievable accuracy of LLMs. Building upon our findings, we propose a training-free Attention Calibration (ACT) technique that automatically optimizes the attention distributions on the fly during inference in an input-adaptive manner. Through extensive experiments, we demonstrate that our proposed ACT technique can enhance the accuracy of the pretrained Llama2-7B-chat by up to 3.16% across various tasks. The source code will be released upon acceptance.

[ICML 2024] When Linear Attention Meets Autoregressive Decoding: Towards More Effective and Efficient Linearized Large Language Models
Haoran You, Yichao Fu, Zheng Wang, Amir Yazdanbakhsh, and Yingyan (Celine) Lin
[Abstract]
Haoran You, Yichao Fu, Zheng Wang, Amir Yazdanbakhsh, and Yingyan (Celine) Lin
[Abstract]
Autoregressive Large Language Models (LLMs) have achieved impressive performance in language tasks but face significant bottlenecks: (1) quadratic complexity bottleneck in the attention module with increasing token numbers, and (2) efficiency bottleneck due to the sequential processing nature of autoregressive LLMs during generation. Linear attention and speculative decoding emerge as solutions for these challenges, yet their applicability and combinatory potential for autoregressive LLMs remain uncertain. To this end, we embark on the first comprehensive empirical investigation into the efficacy of existing linear attention methods for autoregressive LLMs and their integration with speculative decoding. We introduce an augmentation technique for linear attention and ensure the compatibility between linear attention and speculative decoding for efficient LLM training and serving. Extensive experiments and ablation studies on seven existing linear attention works and five encoder/decoder-based LLMs consistently validate the effectiveness of our augmented linearized LLMs, e.g., achieving up to a 6.67 perplexity reduction on LLaMA and 2× speedups during generation as compared to prior linear attention methods.
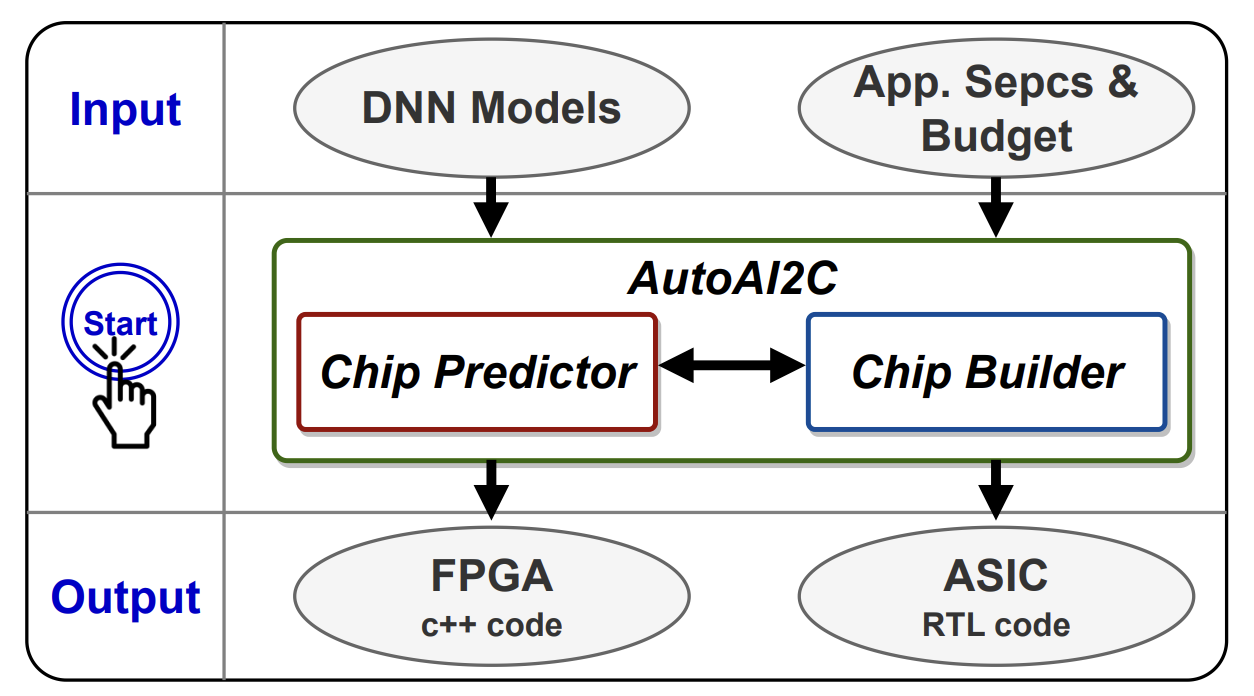
Recent advancements in Deep Neural Networks (DNNs) and the slowing of Moore’s law have made domain-specific hardware accelerators for DNNs (i.e., DNN chips) a promising means for enabling more extensive DNN applications. However, designing DNN chips is challenging due to (1) the vast and non-standardized design space and (2) different DNN models’ varying performance preferences regarding hardware micro-architecture and dataflows. Therefore, designing a DNN chip often takes a large team of inter-disciplinary experts months to years. To enable flexible and efficient DNN chip design, we propose AutoAI2C: a DNN chip generator that can automatically generate both FPGA-and ASIC-based DNN accelerator implementation (i.e., synthesizable hardware and deployment code) with optimized algorithm-to-hardware mapping, given the DNN model specification from mainstream machine learning frameworks (e.g., PyTorch). Specifically, AutoAI2C consists of two major components: (1) a Chip Predictor, which can efficiently and reliably predict a DNN accelerator’s energy, latency, and resource consumption using the proposed graph-based intermediate accelerator representation and (2) a Chip Builder, which can generate and optimize DNN accelerator designs by automatically exploring the design space based on targeting metrics and the Chip Predictor’s performance feedback. Extensive experiments show that our Chip Predictor’s predictions differ by 10% from real-measured ones. Furthermore, AutoAI2C generated accelerators can achieve performance comparable to or better than state-of-the-art accelerators, achieving up to a 2.12× throughput improvements or 2.4× latency reduction with the same level of hardware resource usage, or reducing energy consumption by up to 1.6×, when running the same DNN workloads.
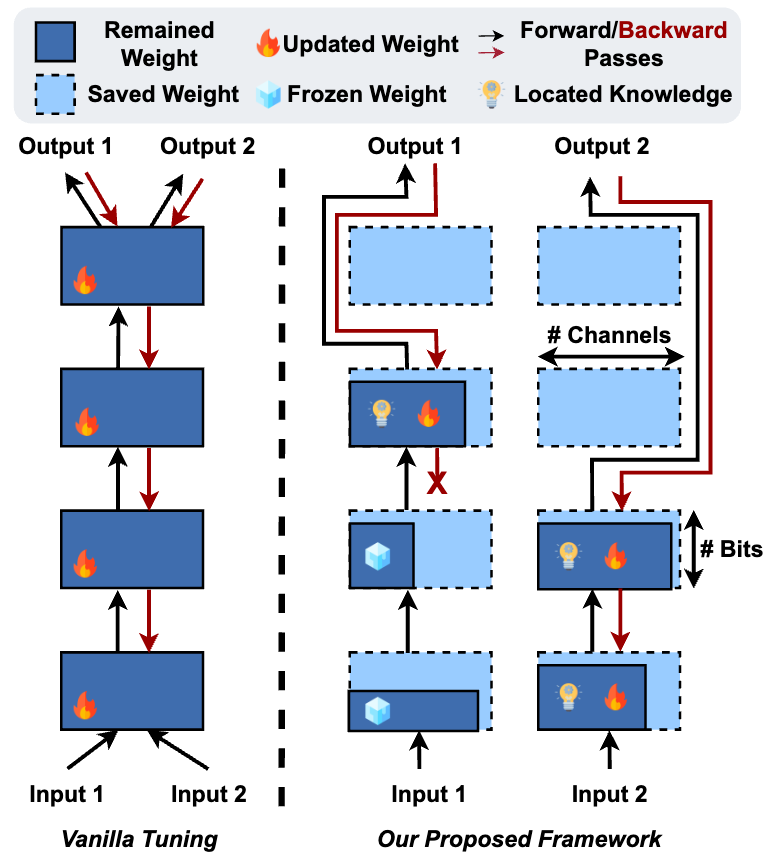
[DAC 2024] EDGE-LLM: Enabling Efficient Large Language Model Adaptation on Edge Devices via Unified Compression and Adaptive Layer Voting
Zhongzhi Yu, Zheng Wang, Yuhan Li, Ruijie Gao, Xiaoya Zhou, Sreenidhi Reddy Bommu, Yang (Katie) Zhao, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Video] [Project Page ]
Zhongzhi Yu, Zheng Wang, Yuhan Li, Ruijie Gao, Xiaoya Zhou, Sreenidhi Reddy Bommu, Yang (Katie) Zhao, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Video] [Project Page ]
Efficiently adapting Large Language Models (LLMs) on resource constrained devices, such as edge GPUs, is vital for applications requiring continuous and privacy-preserving adaptation. However, existing solutions fall short due to the high memory and computational overhead associated with LLMs. To address this, we introduce an LLM tuning framework, Edge-LLM, that features three core components: (1) a layerwise unified compression (LUC) method to reduce computation, offering cost-effective layer-wise pruning ratios and quantization bit-precision policies, (2) an adaptive layer tuning \& voting scheme to reduce memory consumption, that selectively adjusts a subset of layers during each iteration and then adaptively combines their outputs for the final inference, thus reducing backpropagation depth and memory overhead during adaptation, and (3) a complementary hardware scheduling search space that optimizes hardware workload and utilization. Extensive experiments demonstrate that Edge-LLM achieves efficient on-device adaptation with comparable task accuracy as vanilla tuning methods with a 2.92x speed up in each training iteration.
[DAC 2024] 3D-Carbon: An Analytical Carbon Modeling Tool for 3D and 2.5D Integrated Circuits
Yujie Zhao, Yang (Katie) Zhao, Cheng Wan, and Yingyan (Celine) Lin
[Abstract]
Yujie Zhao, Yang (Katie) Zhao, Cheng Wan, and Yingyan (Celine) Lin
[Abstract]
Environmental sustainability is crucial for Integrated Circuits (ICs) across their lifecycle, particularly in manufacturing and use. Meanwhile, ICs using 3D/2.5D integration technologies have emerged as promising solutions to meet the growing demands for computational power. However, there is a distinct lack of carbon modeling tools for 3D/2.5D ICs. Addressing this, we propose 3D-Carbon, an analytical carbon modeling tool designed to quantify the carbon emissions of 3D/2.5D ICs throughout their life cycle. 3D-Carbon factors in both potential savings and overheads from advanced integration technologies, considering practical deployment constraints like bandwidth. We validate 3D-Carbon’s accuracy against established baselines and illustrate its utility through case studies in autonomous vehicles. We believe that 3D-Carbon lays the initial foundation for future innovations in developing environmentally sustainable 3D/2.5D ICs.
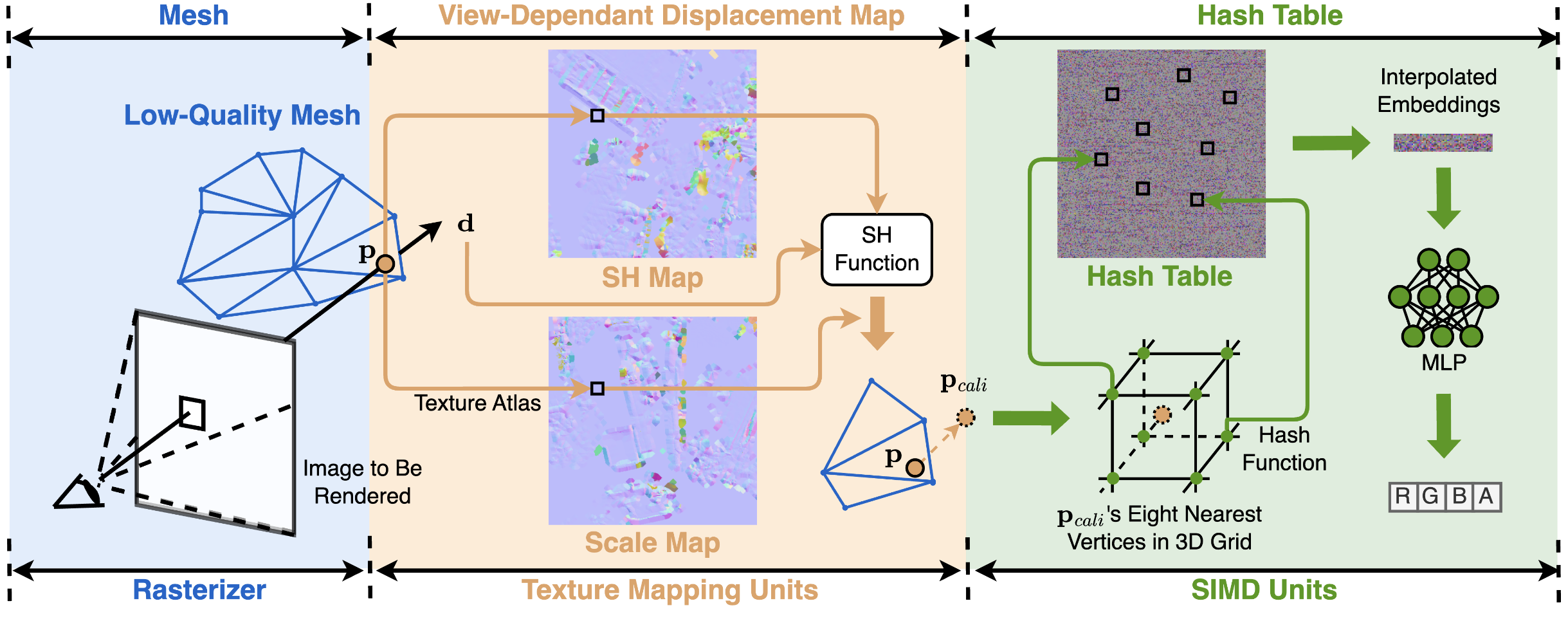
[3DV 2024] MixRT: Mixed Neural Representations For Real-Time NeRF Rendering
Chaojian Li, Bichen Wu, Peter Vajda, and Yingyan (Celine) Lin
[Abstract] [Paper] [Demo] [Project Page]
Chaojian Li, Bichen Wu, Peter Vajda, and Yingyan (Celine) Lin
[Abstract] [Paper] [Demo] [Project Page]
Neural Radiance Field (NeRF) has emerged as a leading technique for novel view synthesis, owing to its impressive photorealistic reconstruction and rendering capability. Nevertheless, achieving real-time NeRF rendering in large-scale scenes has presented challenges, often leading to the adoption of either intricate baked mesh representations with a substantial number of triangles or resource-intensive ray marching in baked representations. We challenge these conventions, observing that high-quality geometry that is represented by meshes with substantial triangles, is not necessary for achieving photorealistic rendering quality. Consequently, we propose MixRT, a novel NeRF representation, that includes a low-quality mesh, a view-dependent-displacement map, and a compressed NeRF model. This design effectively harnesses the capabilities of existing graphics hardware, thus enabling real-time NeRF rendering on edge devices. Leveraging a highly-optimized WebGL-based rendering framework, our proposed MixRT attains real-time rendering speeds on edge devices (>30 FPS at a resolution of 1280 x 720 on a Macbook M1 Pro laptop), betster rendering quality (0.2 PSNR higher on indoor scenes of the Unbounded-360 datasets), and smaller storage (80%) compared to SotA methods.
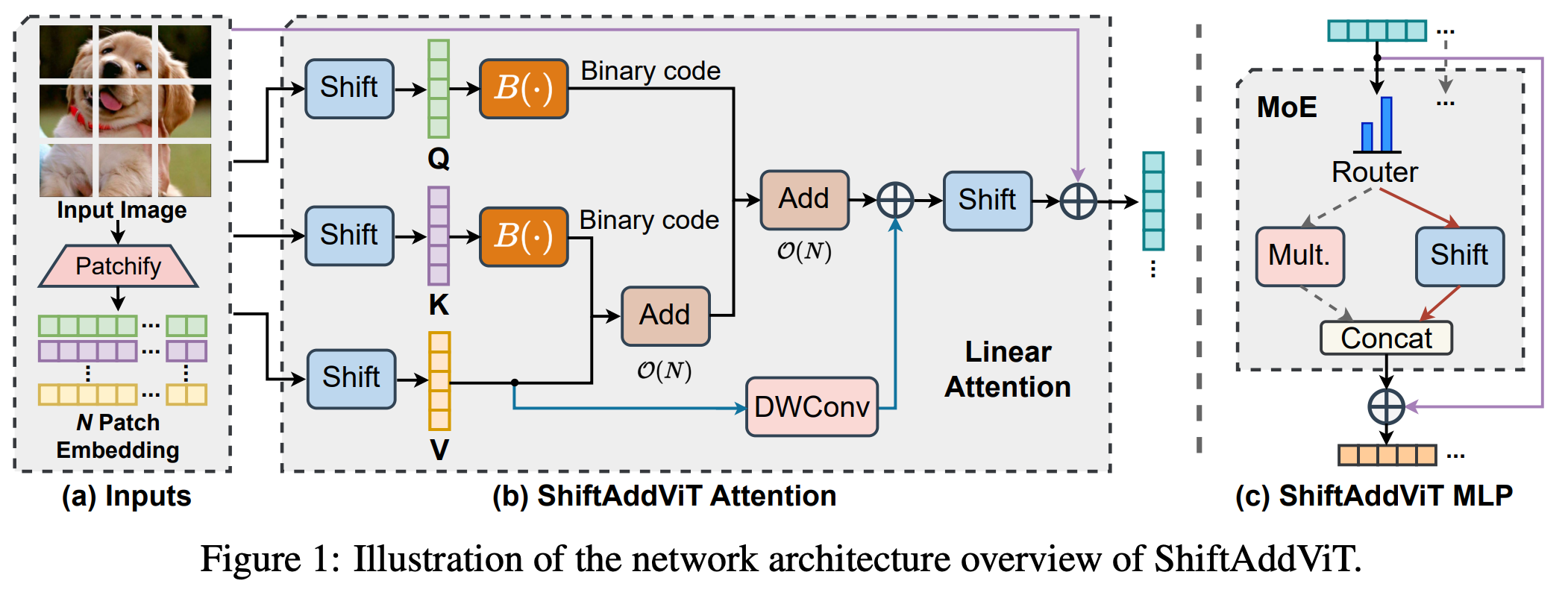
[NeurIPS 2023] ShiftAddViT: Mixture of Multiplication Primitives Towards Efficient Vision Transformer
Haoran You, Huihong Shi, Yipin Guo, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code]
Haoran You, Huihong Shi, Yipin Guo, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code]
Vision Transformers (ViTs) have shown impressive performance and have become a unified backbone for multiple vision tasks. But both attention and multi-layer perceptions (MLPs) in ViTs are not efficient enough due to dense multiplications, resulting in costly training and inference. To this end, we propose to reparameterize the pre-trained ViT with a mixture of multiplication primitives, e.g., bitwise shifts and additions, towards a new type of multiplication-reduced model, dubbed ShiftAddViT, which aims for end-to-end inference speedups on GPUs without the need of training from scratch. Specifically, all 𝙼𝚊𝚝𝙼𝚞𝚕𝚜 among queries, keys, and values are reparameterized by additive kernels, after mapping queries and keys to binary codes in Hamming space. The remaining MLPs or linear layers are then reparameterized by shift kernels. We utilize TVM to implement and optimize those customized kernels for practical hardware deployment on GPUs. We find that such a reparameterization on (quadratic or linear) attention maintains model accuracy, while inevitably leading to accuracy drops when being applied to MLPs. To marry the best of both worlds, we further propose a new mixture of experts (MoE) framework to reparameterize MLPs by taking multiplication or its primitives as experts, e.g., multiplication and shift, and designing a new latency-aware load-balancing loss. Such a loss helps to train a generic router for assigning a dynamic amount of input tokens to different experts according to their latency. In principle, the faster experts run, the larger amount of input tokens are assigned. Extensive experiments consistently validate the effectiveness of our proposed ShiftAddViT, achieving up to 5.18× latency reductions on GPUs and 42.9% energy savings, while maintaining comparable accuracy as original or efficient ViTs.
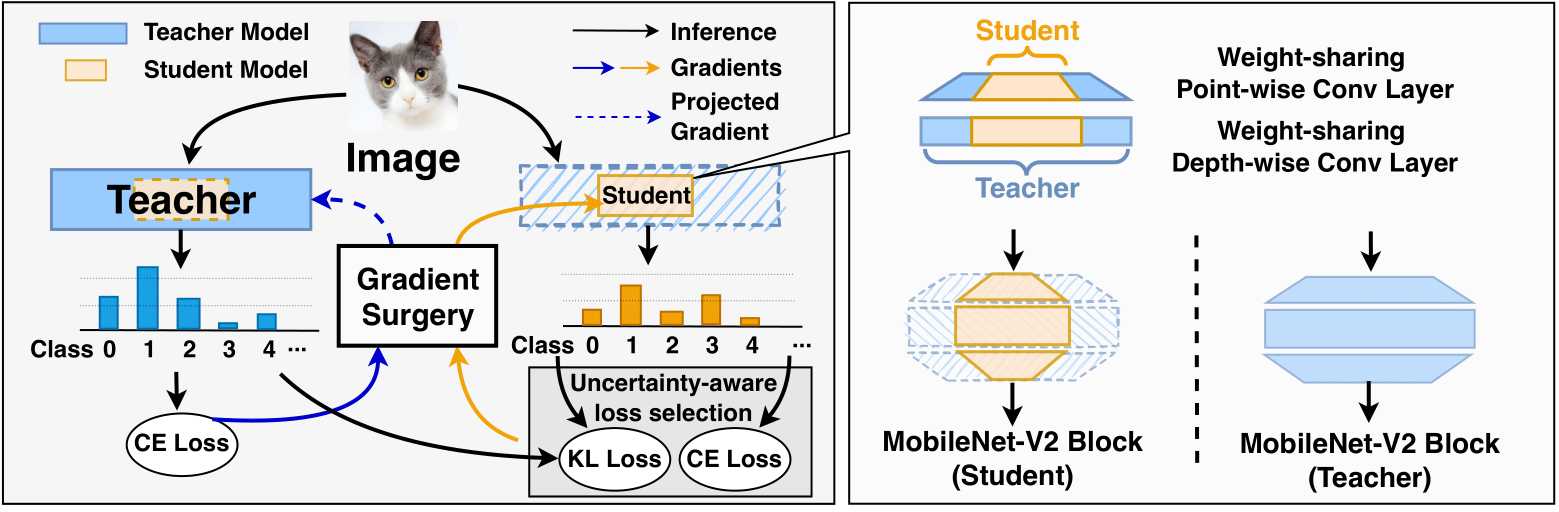
[IEEE Micro 2023] NetDistiller: Empowering Tiny Deep Learning via In-Situ Distillation
Shunyao Zhang, Yonggan Fu, Shang Wu, Jyotikrishna Dass, Haoran You, and Yingyan (Celine) Lin
[Abstract]
Shunyao Zhang, Yonggan Fu, Shang Wu, Jyotikrishna Dass, Haoran You, and Yingyan (Celine) Lin
[Abstract]
Boosting the task accuracy of tiny neural networks (TNNs) has become a fundamental challenge for enabling the deployments of TNNs on edge devices which are constrained by strict limitations in terms of memory, computation, bandwidth, and power supply. To this end, we propose a framework called NetDistiller to boost the achievable accuracy of TNNs by treating them as sub-networks of a weight-sharing teacher constructed by expanding the number of channels of the TNN. Specifically, the target TNN model is jointly trained with the weight-sharing teacher model via (1) gradient surgery to tackle the gradient conflicts between them and (2) uncertainty-aware distillation to mitigate the overfitting of the teacher model. Extensive experiments across diverse tasks validate NetDistiller’s effectiveness in boosting TNNs’ achievable accuracy over state-of-the-art methods.
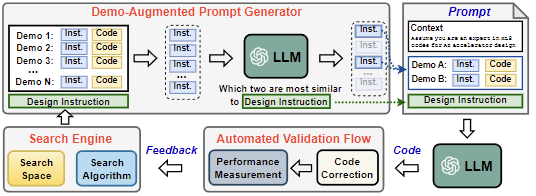
[ICCAD 2023] GPT4AIGChip: Towards Next-Generation AI Accelerator Design Automation via Large Language Models
Yonggan Fu*, Yongan Zhang*, Zhongzhi Yu*, Sixu Li, Zhifan Ye, Chaojian Li, Cheng Wan, and Yingyan (Celine) Lin
[Abstract] [Paper]
Yonggan Fu*, Yongan Zhang*, Zhongzhi Yu*, Sixu Li, Zhifan Ye, Chaojian Li, Cheng Wan, and Yingyan (Celine) Lin
[Abstract] [Paper]
The remarkable capabilities and intricate nature of Artificial Intelligence (AI) have dramatically escalated the imperative for specialized AI accelerators. Nonetheless, designing these accelerators for various AI workloads remains both labor- and time-intensive. While existing design exploration and automation tools can partially alleviate the need for extensive human involvement, they still demand substantial hardware expertise, posing a barrier to non-experts and stifling AI accelerator development. Motivated by the astonishing potential of large language models (LLMs) for generating high-quality content in response to human language instructions, we embark on this work to examine the possibility of harnessing LLMs to automate AI accelerator design. Through this endeavor, we develop GPT4AIGChip, a framework intended to democratize AI accelerator design by leveraging human natural languages instead of domain-specific languages. Specifically, we first perform an in-depth investigation into LLMs’ limitations and capabilities for AI accelerator design, thus aiding our understanding of our current position and garnering insights into LLM-powered automated AI accelerator design. Furthermore, drawing inspiration from the above insights, we develop the GPT4AIGChip framework, which features an automated demo-augmented prompt-generation pipeline utilizing in-context learning to guide LLMs towards creating high-quality AI accelerator design. To our knowledge, this work is the first to demonstrate an effective pipeline for LLM-powered automated AI accelerator generation. Accordingly, we anticipate that our insights and framework can serve as a catalyst for innovations in next-generation LLM-powered design automation tools.
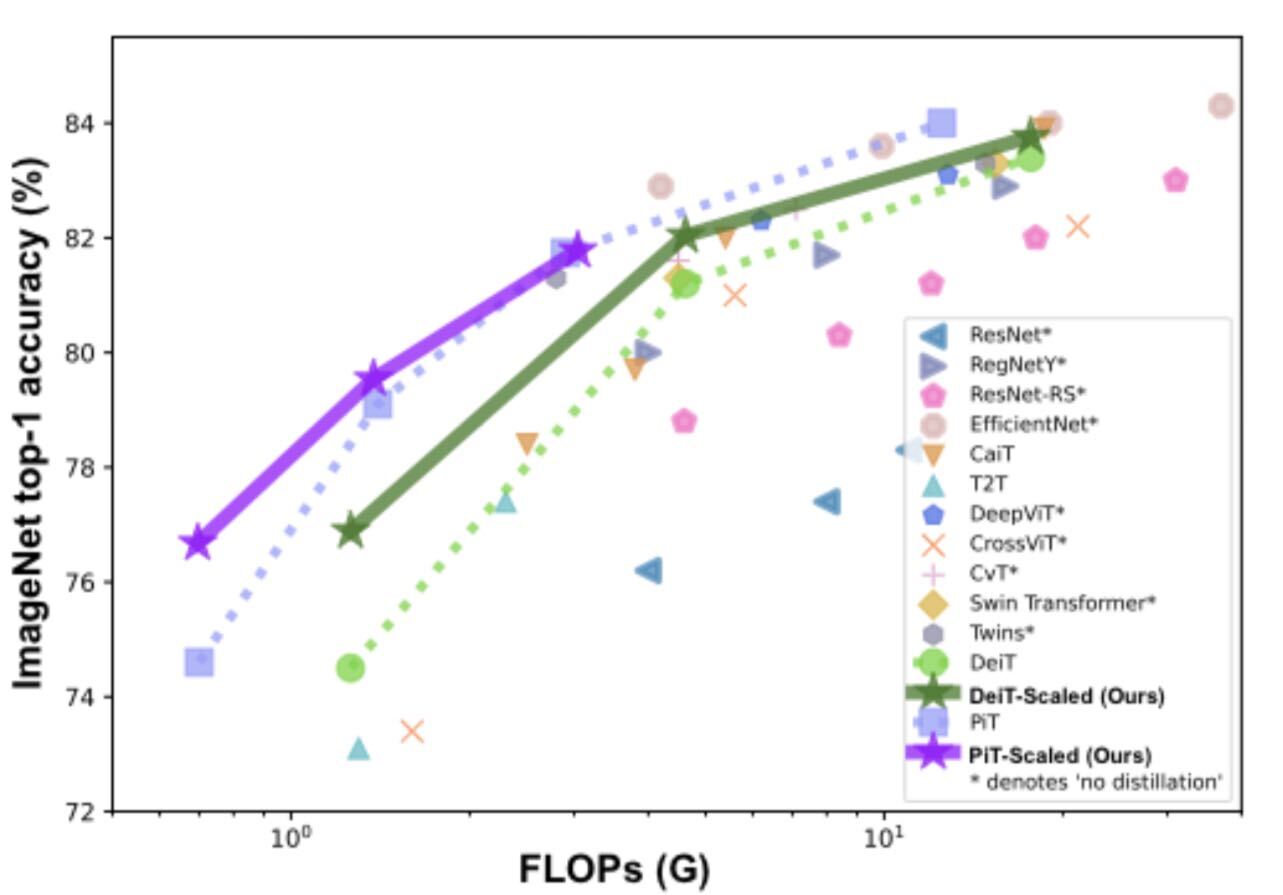
[TECS 2023] An Investigation on Hardware-Aware Vision Transformer Scaling
Chaojian Li, Kyungmin Kim, Bichen Wu, Peizhao Zhang, Hang Zhang, Xiaoliang Dai, Peter Vajda, and Yingyan (Celine) Lin
[Abstract] [Paper]
Chaojian Li, Kyungmin Kim, Bichen Wu, Peizhao Zhang, Hang Zhang, Xiaoliang Dai, Peter Vajda, and Yingyan (Celine) Lin
[Abstract] [Paper]
Vision Transformer (ViT) has demonstrated promising performance in various computer vision tasks, and recently attracted a lot of research attention. Many recent works have focused on proposing new architectures to improve ViT and deploying it into real-world applications. However, little effort has been made to analyze and understand ViT’s architecture design space and its implication of hardware-cost on different devices. In this work, by simply scaling ViT's depth, width, input size, and other basic configurations, we show that a scaled vanilla ViT model without bells and whistles can achieve comparable or superior accuracy-efficiency trade-off than most of the latest ViT variants. Specifically, compared to DeiT-Tiny, our scaled model achieves a +1.9% higher ImageNet top-1 accuracy under the same FLOPs and a +3.7% better ImageNet top-1 accuracy under the same latency on an NVIDIA Edge GPU TX2. Motivated by this, we further investigate the extracted scaling strategies from the following two aspects: (1) can these scaling strategies be transferred across different real hardware devices; and (2) can these scaling strategies be transferred to different ViT variants and tasks? For (1), our exploration, based on various devices with different resource budgets, indicates that the transferability effectiveness depends on the underlying device together with its corresponding deployment tool; for (2), we validate the effective transferability of the aforementioned scaling strategies obtained from a vanilla ViT model on top of an image classification task to the PiT model, a strong ViT variant targeting efficiency, as well as object detection and video classification tasks. In particular, when transferred to PiT, our scaling strategies lead to a boosted ImageNet top-1 accuracy of from 74.6% to 76.7% (+2.1%) under the same 0.7G FLOPs; and when transferred to the COCO object detection task, the average precision is boosted by +0.7% under a similar throughput on a V100 GPU.
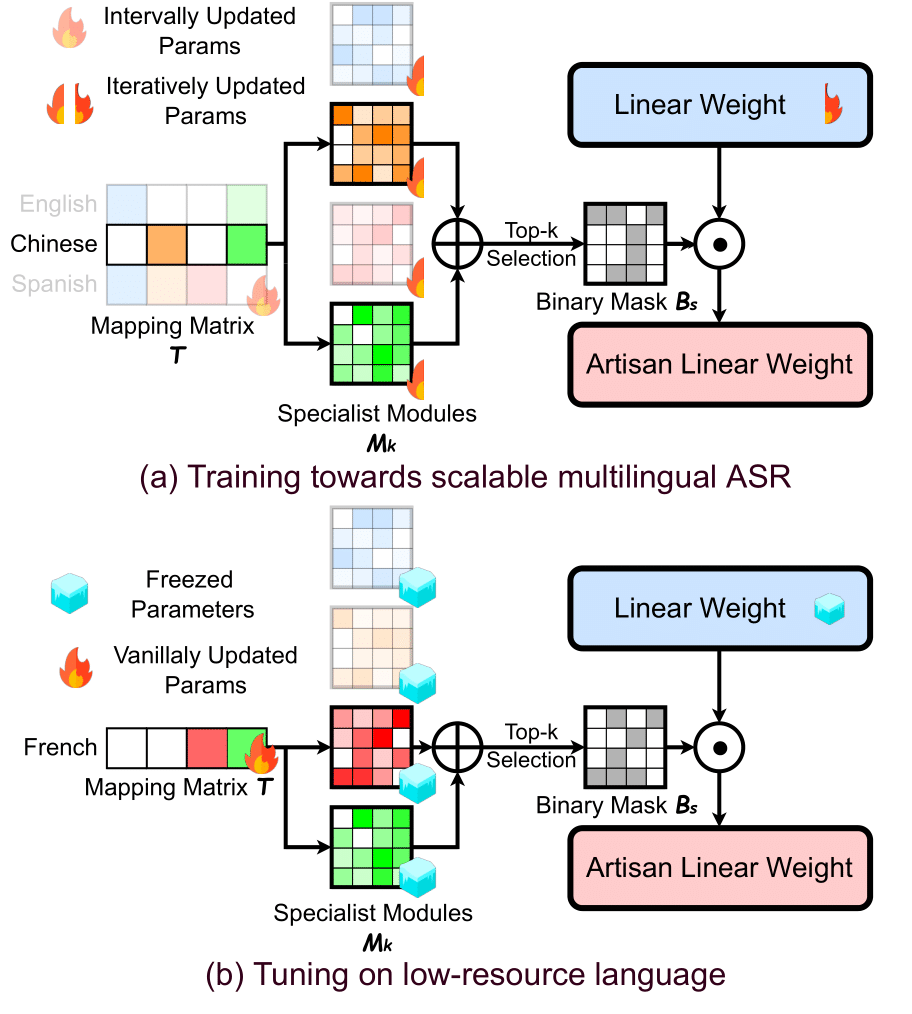
[ICML 2023] Master-ASR: Achieving Multilingual Scalability and Low-Resource Adaptation in ASR with Modularized Learning
Zhongzhi Yu, Yang Zhang, Kaizhi Qian, Cheng Wan, Yonggan Fu, Yongan Zhang, and Yingyan (Celine) Lin
[Abstract] [Paper] [Video] [Project Page]
Zhongzhi Yu, Yang Zhang, Kaizhi Qian, Cheng Wan, Yonggan Fu, Yongan Zhang, and Yingyan (Celine) Lin
[Abstract] [Paper] [Video] [Project Page]
Despite the impressive performance achieved by automatic speech recognition (ASR) recently, we observe that there are still two challenges in ASR, hindering its wider applications: (1) the difficulty of introducing scalability into the model for supporting more languages with limited training, inference, and storage overhead, and (2) the low-resource adaptation ability to enable effective low-resource adaptation while avoiding over-fitting and catastrophic forgetting issues. Inspired by the recent findings, we hypothesize that we can tackle the above challenges with widely shared modules across languages. To this end, we propose an ASR framework, dubbed Master-ASR, that, for the first time, simultaneously achieves strong multilingual scalability and low-resource adaptation ability in a modularized-then-assemble manner. Specifically, Master-ASR learns a small set of generalized sub-modules and adaptively assembles them for different languages to reduce the multilingual overhead and enable effective knowledge transfer for low-resource adaptation. Extensive experiments and visualizations prove that Master-ASR can effectively discover language similarity and improve multilingual and low-resource ASR performance over state-of-the-art (SOTA) methods (e.g., a 0.13~2.41 lower CER with 30% less inference overhead over SOTA solutions on multilingual ASR and a comparable CER with nearly 500 times less trainable parameters over SOTA solutions on low-resource tuning, respectively).
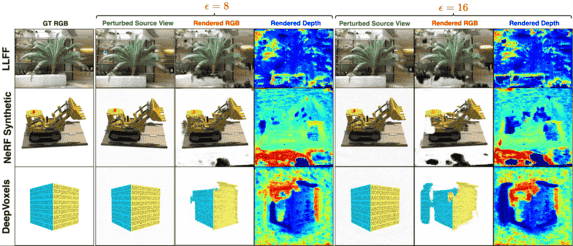
[ICML 2023] NeRFool: Uncovering the Vulnerability of Generalizable Neural Radiance Fields against Adversarial Perturbations
Yonggan Fu, Ye Yuan, Souvik Kundu, Shang Wu, Shunyao Zhang, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Video]
Yonggan Fu, Ye Yuan, Souvik Kundu, Shang Wu, Shunyao Zhang, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Video]
Generalizable Neural Radiance Fields (GNeRF) are one of the most promising real-world solutions for novel view synthesis, thanks to their cross-scene generalization capability and thus the possibility of instant rendering on new scenes. While adversarial robustness is essential for real-world applications, little study has been devoted to understanding its implication on GNeRF. We hypothesize that because GNeRF is implemented by conditioning on the source views from new scenes, which are often acquired from the Internet or third-party providers, there are potential new security concerns regarding its real-world applications. Meanwhile, existing understanding and solutions for neural networks' adversarial robustness may not be applicable to GNeRF, due to its 3D nature and uniquely diverse operations. To this end, we present NeRFool/NeRFool$^+$, which to the best of our knowledge are the first works that set out to understand the adversarial robustness of GNeRF. Specifically, NeRFool unveils the vulnerability patterns and important insights regarding GNeRF's adversarial robustness; Built upon the above insights gained from NeRFool, we further develop NeRFool$^+$, which integrates three techniques that can effectively attack GNeRF across a wide range of target views, and provide guidelines for defending against our proposed NeRFool$^+$ attacks. We believe that our NeRFool/NeRFool$^+$ lays the initial foundation for future innovations in developing robust real-world GNeRF solutions.
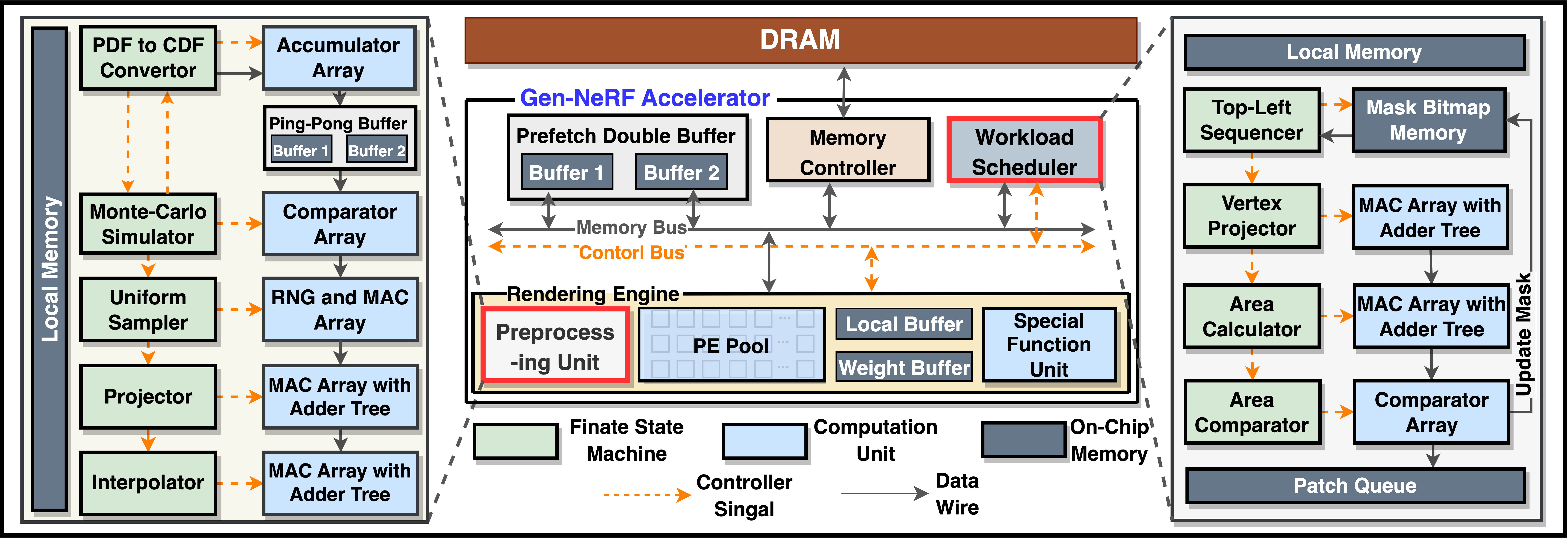
[ISCA 2023] Gen-NeRF: Efficient and Generalizable Neural Radiance Fields via Algorithm-Hardware Co-Design
Yonggan Fu, Zhifan Ye, Jiayi Yuan, Shunyao Zhang, Sixu Li, Haoran You, and Yingyan (Celine) Lin
[Abstract] [Paper] [Video]
Yonggan Fu, Zhifan Ye, Jiayi Yuan, Shunyao Zhang, Sixu Li, Haoran You, and Yingyan (Celine) Lin
[Abstract] [Paper] [Video]
Novel view synthesis is an essential functionality for enabling immersive experiences in various Augmented- and Virtual-Reality (AR/VR) applications like the Metaverse, for which Neural Radiance Field (NeRF) has emerged as the state-of-the-art technique. In particular, generalizable NeRFs have gained increasing popularity thanks to their cross-scene generalizable capability, which enables NeRFs to be instantly serviceable for new scenes without per-scene training. Despite their promise, generalizable NeRFs aggravate the prohibitive complexity of NeRFs due to extra memory accesses needed to acquire scene features, causing NeRFs’ ray marching process to be memory-bounded. To this end, we propose Gen-NeRF, an algorithm-hardware co-design framework dedicated to generalizable NeRF acceleration, aiming to win both rendering efficiency and generalization capability in NeRFs. To the best of our knowledge, Gen-NeRF is the first to enable real-time generalizable NeRFs, demonstrating a promising NeRF solution for next-generation AR/VR devices. On the algorithm side, Gen-NeRF integrates a coarse-then-focus volume sampling strategy, leveraging the fact that different regions of a 3D scene can feature diverse sparsity ratios depending on where the objects are located in the scene to enable sparse yet effective sampling. On the hardware side, Gen-NeRF highlights an accelerator micro-architecture to maximize the data reuse opportunities among different rays by making use of their epipolar geometric relationship. Furthermore, our Gen-NeRF accelerator features a customized dataflow to enhance data locality during point-to-hardware mapping and an optimized scene feature storage strategy to minimize memory bank conflicts across camera rays. Extensive experiments validate Gen-NeRF's effectiveness in enabling real-time and generalizable novel view synthesis.
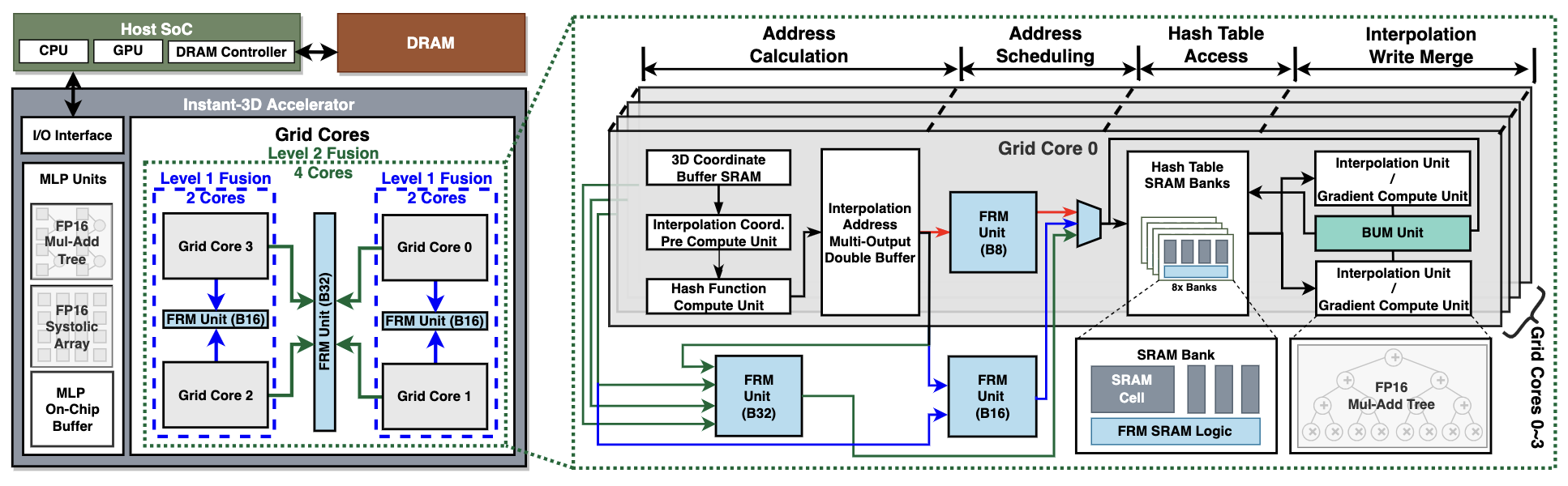
[ISCA 2023] Instant-3D: Instant Neural Radiance Fields Training Towards Real-Time AR/VR 3D Reconstruction
Sixu Li, Chaojian Li, Wenbo Zhu, Boyang (Tony) Yu, Yang Zhao, Cheng Wan, Haoran You, Huihong Shi, and Yingyan (Celine) Lin
[Abstract] [Paper] [Video]
Sixu Li, Chaojian Li, Wenbo Zhu, Boyang (Tony) Yu, Yang Zhao, Cheng Wan, Haoran You, Huihong Shi, and Yingyan (Celine) Lin
[Abstract] [Paper] [Video]
Neural Radiance Field (NeRF) based 3D reconstruc- tion is highly desirable for immersive Augmented and Virtual Reality (AR/VR) applications, but instant (i.e., < 5 seconds) on- device NeRF training remains a challenge. In this work, we first identify the inefficiency bottleneck: the need to interpolate NeRF embeddings up to 200,000 times from a 3D embedding grid dur- ing each training iteration. To alleviate this, we propose Instant- 3D, an algorithm-hardware co-design acceleration framework that achieves instant on-device NeRF training. Our algorithm decomposes the embedding grid representation in terms of color and density, enabling computational redundancy to be squeezed out by adopting different (1) grid sizes and (2) update frequencies for the color and density branches. Our hardware accelerator further reduces the dominant memory accesses for embedding grid interpolation by (1) mapping multiple nearby points’ mem- ory read requests into one during the feed-forward process, (2) merging embedding grid updates from the same sliding time window during back-propagation, and (3) fusing different computation cores to support different grid sizes needed by the color and density branches of Instant-3D algorithm. Extensive experiments validate the effectiveness of our proposed Instant- 3D, achieving a large training runtime reduction of 41× - 248× while maintaining the same reconstruction quality. Excitingly, Instant-3D has fulfilled the goal of instant 3D reconstruction for AR/VR, requiring only 1.6 seconds per scene and meeting the AR/VR power consumption constraint of 1.9 W.
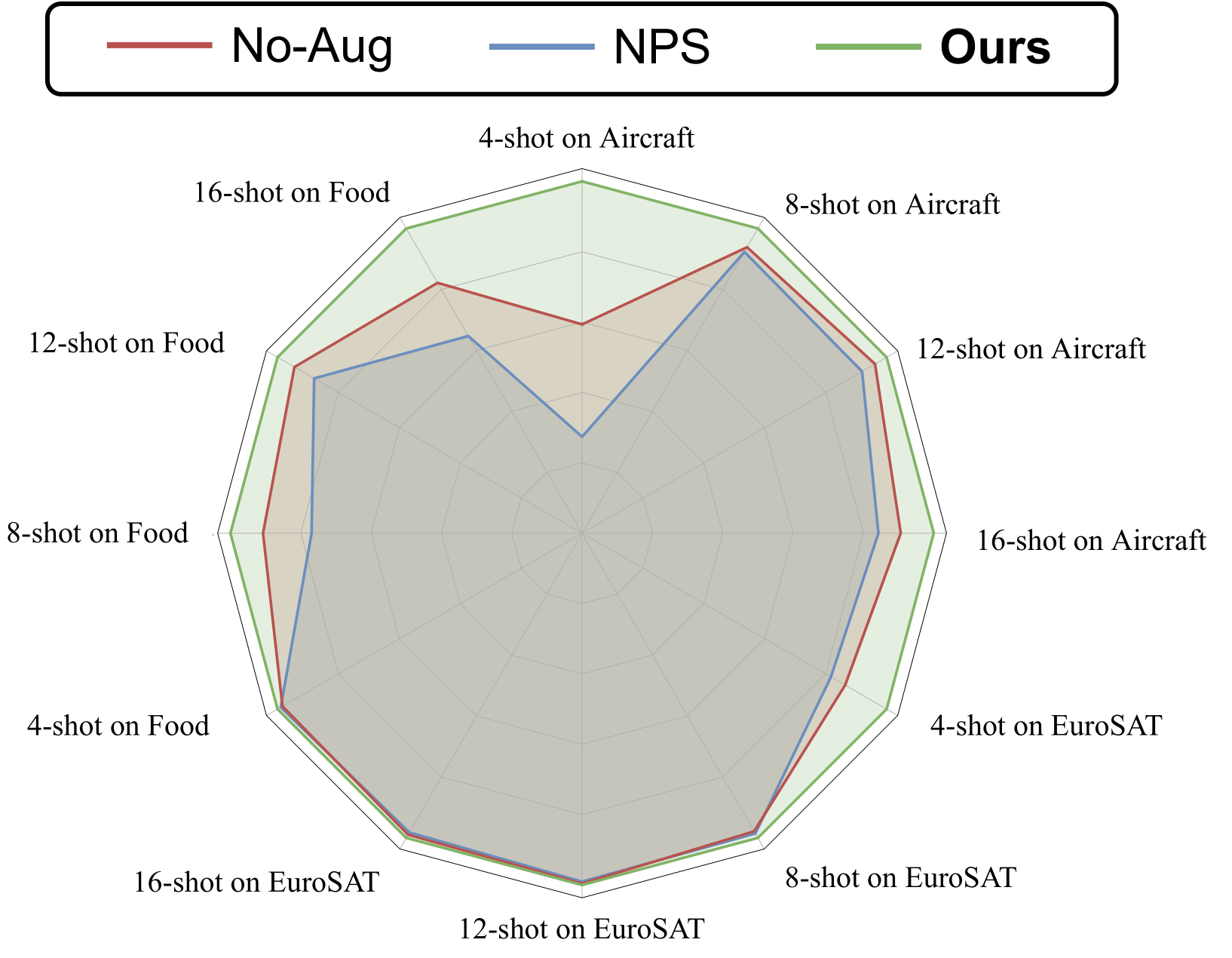
[CVPR 2023] Hint-Aug: Drawing Hints from Vision Foundation Models towards Boosted Few-shot Parameter-Efficient ViT Tuning
Zhongzhi Yu, Shang Wu, Yonggan Fu, Cheng Wan, Shunyao Zhang, Chaojian Li, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Project Page]
Zhongzhi Yu, Shang Wu, Yonggan Fu, Cheng Wan, Shunyao Zhang, Chaojian Li, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Project Page]
Despite the promise of finetuning foundation vision transformers (ViTs) on downstream tasks, existing techniques are still not satisfactory under few-shot scenarios due to the data-hungry nature of ViTs. To tackle this, previous data augmentation techniques fall short because of the limited features contained in few-shot training data. We first identify an opportunity for few-shot tuning foundation ViT models: pretrained ViTs themselves have already learned highly representative features which are not updated during finetuning. We thus hypothesize the possibility of leveraging those learned features to augment the few-shot training data for boosting the effectiveness of finetuning pretrained foundation ViTs. To this end, we propose a framework called Hint-based Data Augmentation (Hint-Aug), which is dedicated to boosting the effectiveness of few-shot tuning foundation ViT models. Hint-Aug is achieved by augmenting the over-fitted parts of training samples with the learned features of pretrained ViT models. Specifically, Hint-Aug integrates two key enablers: (1) an Attentive Over-fitting Detector (AOD) to detect over-confident patches of foundation ViTs for potentially alleviating their over-fitting of the few-shot training set and (2) a Confusion-based Feature Infusion (CFI) module to infuse easy-to-confuse features from the given pretrained foundation ViT with the aforementioned detected over-confident patches for enhancing the feature diversity during finetuning. Extensive experiments and ablation studies on seven datasets, and three parameter-efficient tuning techniques consistently validate Hint-Aug's effectiveness: 0.04% ~ 6.89% higher accuracy over the state-of-the-art (SOTA) data augmentation methods. Specifically, on the Pet dataset, Hint-Aug achieves a 2.22% higher accuracy with 50% less training data over SOTA data augmentation methods.
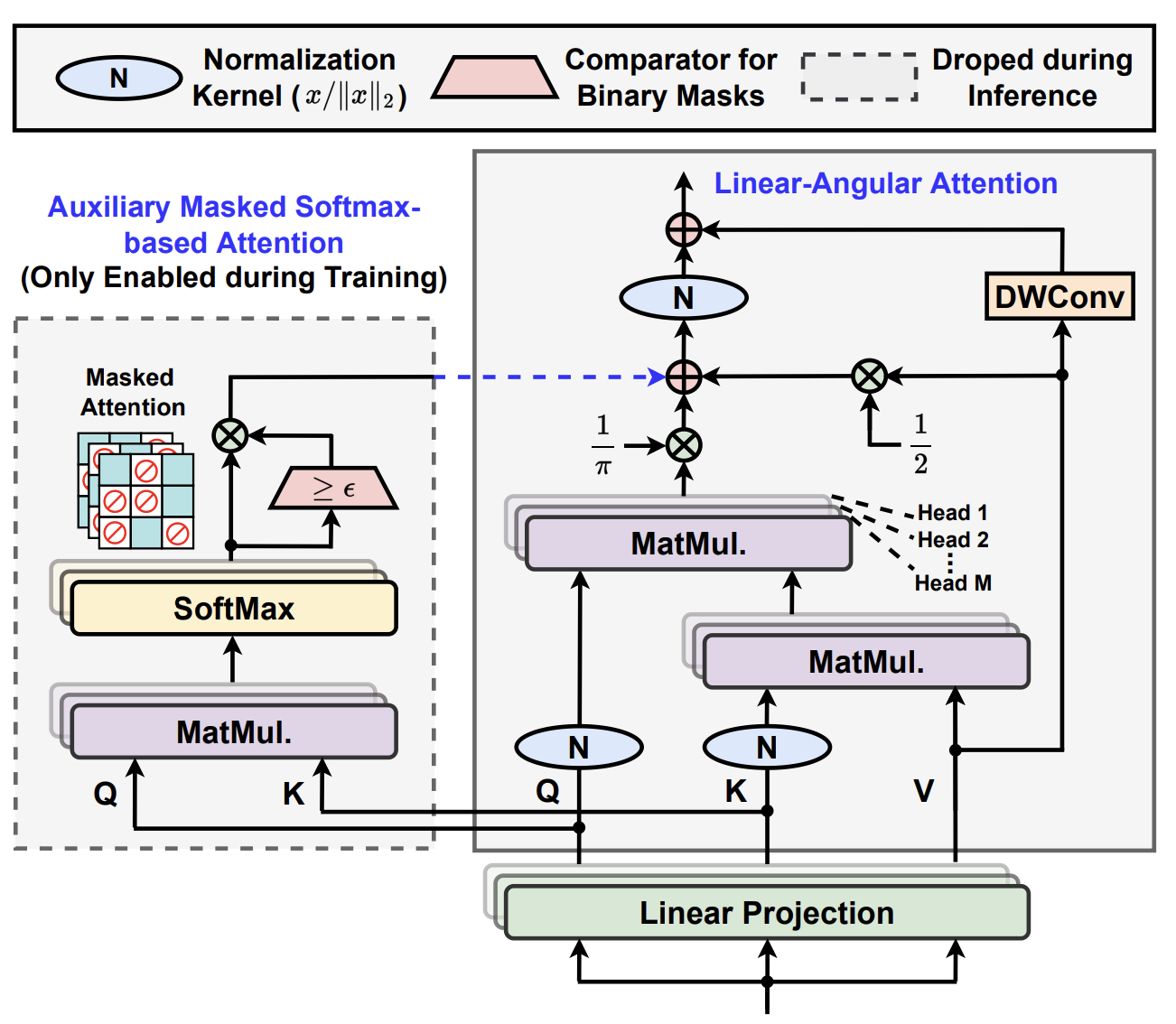
[CVPR 2023] Castling-ViT: Compressing Self-Attention via Switching Towards Linear-Angular Attention During Vision Transformer Inference
Haoran You, Yunyang Xiong, Xiaoliang Dai, Bichen Wu, Peizhao Zhang, Haoqi Fan, Peter Vajda, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Video] [Project Page] [Slides]
Haoran You, Yunyang Xiong, Xiaoliang Dai, Bichen Wu, Peizhao Zhang, Haoqi Fan, Peter Vajda, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Video] [Project Page] [Slides]
Vision Transformers (ViTs) have shown impressive performance but still require a high computation cost as compared to convolutional neural networks (CNNs), due to the global similarity measurements and thus a quadratic complexity with the input tokens. Existing efficient ViTs adopt local attention (e.g., Swin) or linear attention (e.g., Performer), which sacrifice ViTs' capabilities of capturing either global or local context. In this work, we ask an important research question: Can ViTs learn both global and local context while being more efficient during inference? To this end, we propose a framework called Castling-ViT, which trains ViTs using both linear-angular attention and masked softmax-based quadratic attention, but then switches to having only linear angular attention during ViT inference. Our Castling-ViT leverages angular kernels to measure the similarities between queries and keys via spectral angles. And we further simplify it with two techniques: (1) a novel linear-angular attention mechanism: we decompose the angular kernels into linear terms and high-order residuals, and only keep the linear terms; and (2) we adopt two parameterized modules to approximate high-order residuals: a depthwise convolution and an auxiliary masked softmax attention to help learn both global and local information, where the masks for softmax attention are regularized to gradually become zeros and thus incur no overhead during ViT inference. Extensive experiments and ablation studies on three tasks consistently validate the effectiveness of the proposed Castling-ViT, e.g., achieving up to a 1.8% higher accuracy or 40% MACs reduction on ImageNet classification and 1.2 higher mAP on COCO detection under comparable FLOPs, as compared to ViTs with vanilla softmax-based attentions.
[CVPR 2023] Auto-CARD: Efficient and Robust Codec Avatar Driving for Real-time Mobile Telepresence
Yonggan Fu, Yuecheng Li, Chenghui Li, Jason Saragih, Peizhao Zhang, Xiaoliang Dai, and Yingyan (Celine) Lin
[Abstract] [Paper] [Video]
Yonggan Fu, Yuecheng Li, Chenghui Li, Jason Saragih, Peizhao Zhang, Xiaoliang Dai, and Yingyan (Celine) Lin
[Abstract] [Paper] [Video]
Real-time and robust photorealistic avatars for telepresence in AR/VR have been highly desired for enabling immersive photorealistic telepresence. However, there still exists one key bottleneck: the considerable computational expense needed to accurately infer facial expressions captured from headset-mounted cameras with a quality level that can match the realism of the avatar's human appearance. To this end, we propose a framework called Auto-CARD, which for the first time enables real-time and robust driving of Codec Avatars when exclusively using merely on-device computing resources. This is achieved by minimizing two sources of redundancy. First, we develop a dedicated neural architecture search technique called AVE-NAS for avatar encoding in AR/VR, which explicitly boosts both the searched architectures' robustness in the presence of extreme facial expressions and hardware friendliness on fast evolving AR/VR headsets. Second, we leverage the temporal redundancy in consecutively captured images during continuous rendering and develop a mechanism dubbed LATEX to skip the computation of redundant frames. Specifically, we first identify an opportunity from the linearity of the latent space derived by the avatar decoder and then propose to perform adaptive latent extrapolation for redundant frames. For evaluation, we demonstrate the efficacy of our Auto-CARD framework in real-time Codec Avatar driving settings, where we achieve a 5.05$\times$ speed-up on Meta Quest 2 while maintaining a comparable or even better animation quality than state-of-the-art avatar encoder designs.
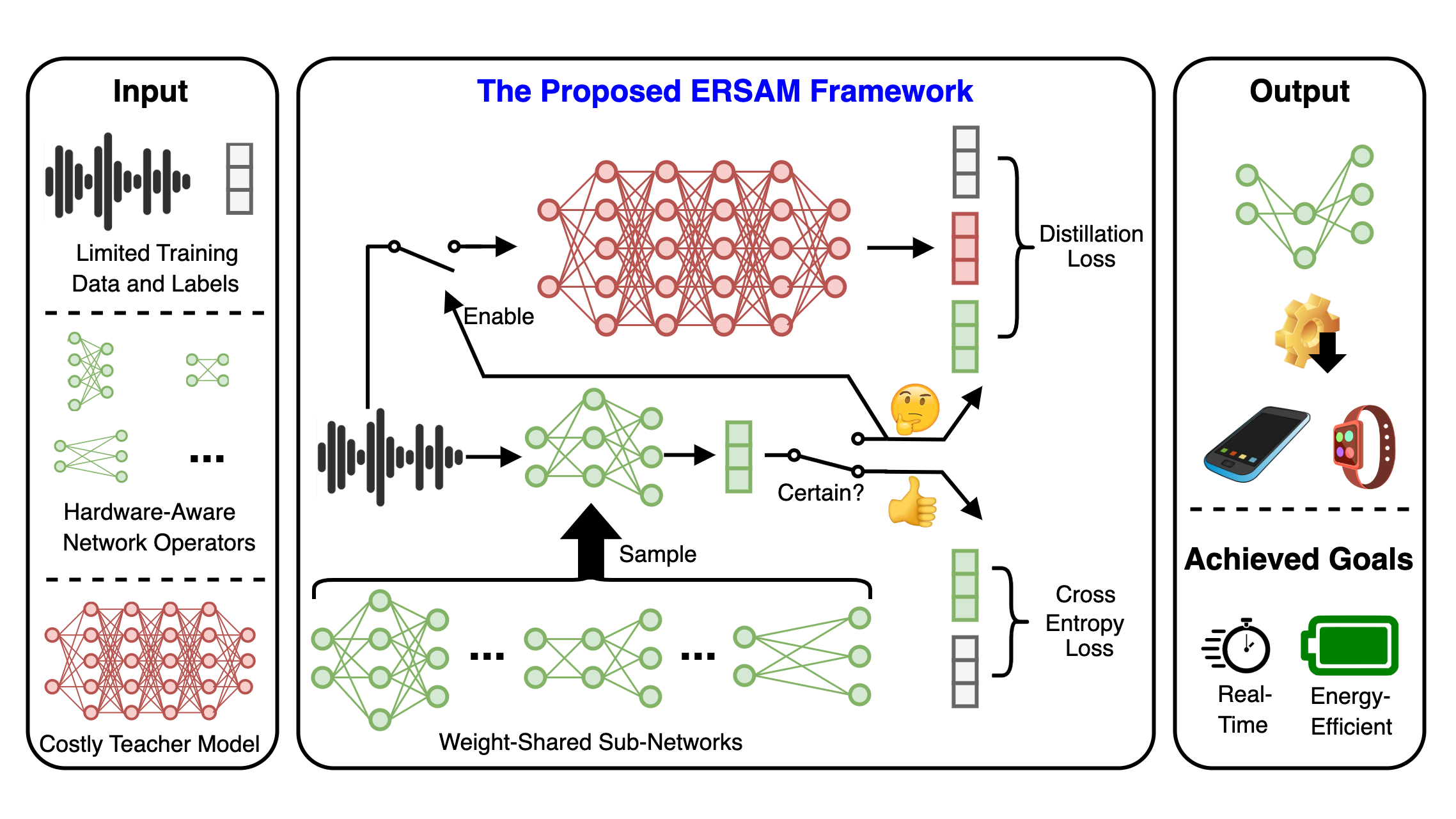
[ICASSP 2023] ERSAM: Neural Architecture Search For Energy-Efficient and Real-Time Social Ambiance Measurement
Chaojian Li, Wenwan Chen, Jiayi Yuan, Yingyan (Celine) Lin, and Ashutosh Sabharwal
[Abstract] [Paper]
Chaojian Li, Wenwan Chen, Jiayi Yuan, Yingyan (Celine) Lin, and Ashutosh Sabharwal
[Abstract] [Paper]
Social ambiance describes the context in which social interac- tions happen, and can be measured using speech audio by counting the number of the concurrent speakers. This measurement has en- abled various mental health tracking and human-centric IoT applica- tions. While on-device Socal Ambiance Measure (SAM) is highly desirable to ensure user privacy and thus facilitate wide adoption of the aforementioned applications, the required computational com- plexity of state-of-the-art deep neural networks (DNNs) powered SAM solutions stands at odds with the often constrained resources on mobile devices. Furthermore, only limited labeled data is avail- able or practical when it comes to SAM under clinical settings due to various privacy constraints and the required human effort, further challenging the achievable accuracy of on-device SAM solutions. To this end, we propose a dedicated neural architecture search frame- work for Energy-efficient and Real-time SAM (ERSAM). Specifi- cally, our ERSAM framework can automatically search for DNNs that push forward the achievable accuracy vs. hardware efficiency frontier of mobile SAM solutions. For example, ERSAM-delivered DNNs only consume 40 mW · 12 h energy and 0.05 seconds pro- cessing latency for a 5 seconds audio segment on a Pixel 3 phone, while only achieving an error rate of 14.3% on a social ambiance dataset generated by LibriSpeech. We can expect that our ERSAM framework can pave the way for ubiquitous on-device SAM solu- tions which are in growing demand.
[DAC 2023] Robust Tickets Can Transfer Better: Drawing More Transferable Subnetworks in Transfer Learning
Yonggan Fu, Ye Yuan, Shang Wu, Jiayi Yuan, and Yingyan (Celine) Lin
[Abstract] [Paper]
Yonggan Fu, Ye Yuan, Shang Wu, Jiayi Yuan, and Yingyan (Celine) Lin
[Abstract] [Paper]
Transfer learning leverages feature representations of deep neural networks (DNNs) pretrained on rich source tasks to empower the finetuning on downstream tasks, whereas pretrained models are often prohibitively large for delivering generalizable representations, which limits their deployment on edge devices. To close this gap, driven by the lottery ticket hypothesis, we interestingly find that robust tickets can transfer better, i.e., subnetworks drawn with properly induced adversarial robustness can win better transferability over vanilla lottery tickets. Our proposed transfer learning pipelines can achieve enhanced accuracy-sparsity trade-offs across diverse tasks and sparsity patterns on downstream tasks and enrich the lottery ticket hypothesis.
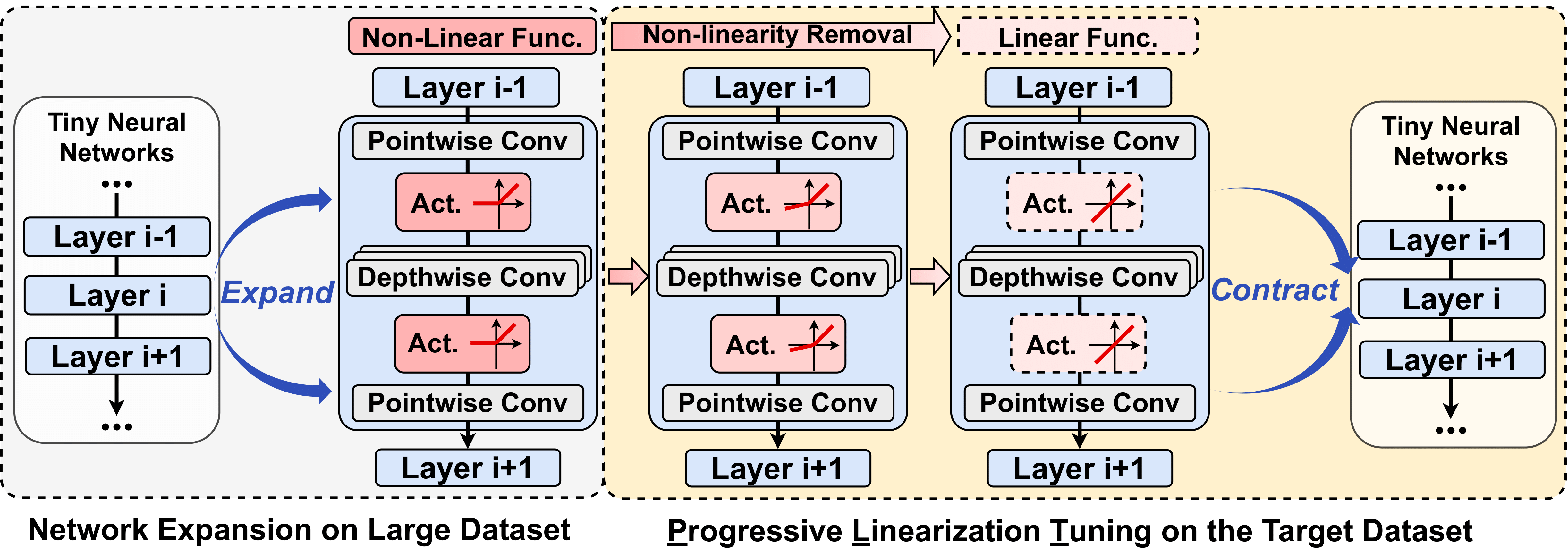
[DAC 2023] NetBooster: Empowering Tiny Deep Learning By Standing on the Shoulders of Deep Giants
Zhongzhi Yu, Yonggan Fu, Jiayi Yuan, Haoran You, and Yingyan (Celine) Lin
[Abstract] [Paper]
Zhongzhi Yu, Yonggan Fu, Jiayi Yuan, Haoran You, and Yingyan (Celine) Lin
[Abstract] [Paper]
Tiny deep learning has attracted increasing attention driven by the substantial demand for deploying deep learning on numerous intelligent Internet-of-Things devices. However, it is still challenging to unleash tiny deep learning's full potential on both large-scale datasets and downstream tasks due to the under-fitting issues caused by the limited model capacity of tiny neural networks (TNNs). To this end, we propose a framework called NetBooster to empower tiny deep learning by augmenting the architectures of TNNs via an expansion-then-contraction strategy. Extensive experiments show that NetBooster consistently outperforms state-of-the-art tiny deep learning solutions.
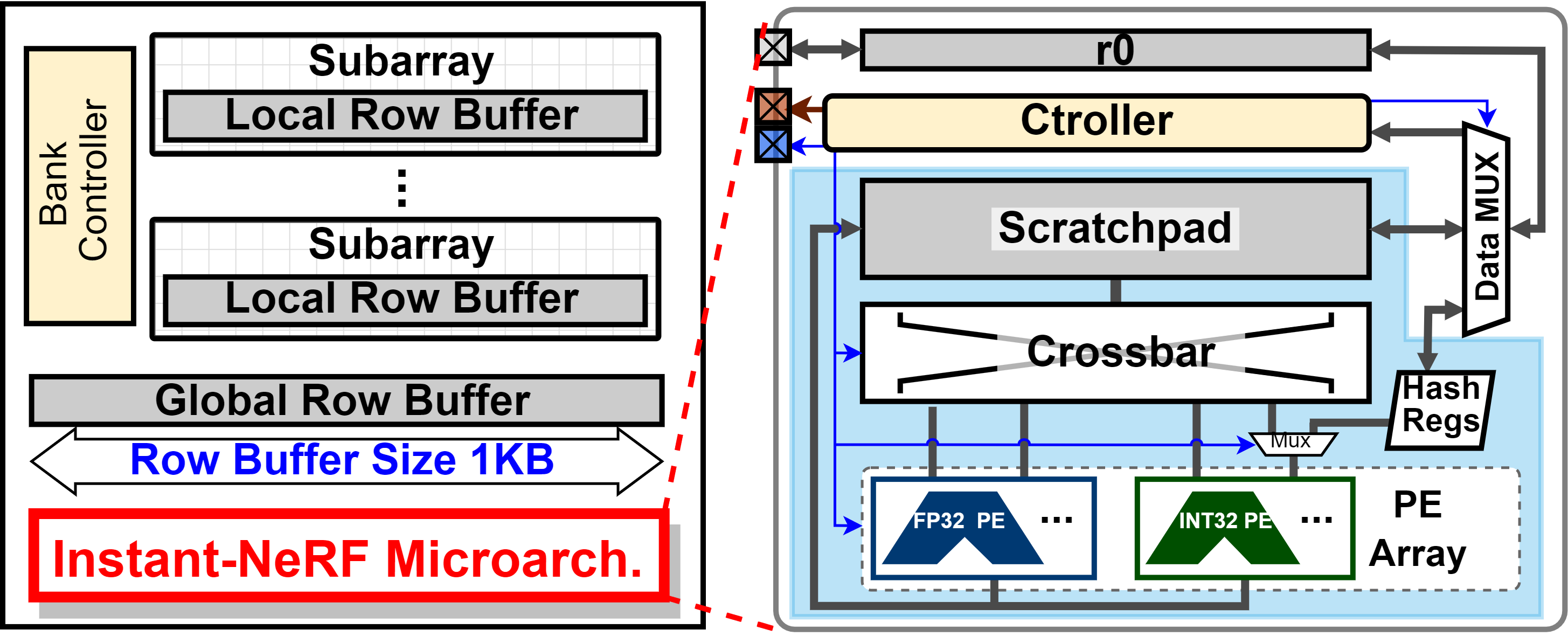
[DAC 2023] Instant-NeRF: Instant On-Device Neural Radiance Field Training via Algorithm-Accelerator Co-Designed Near-Memory Processing
Yang Zhao, Shang Wu, Jingqun Zhang, Sixu Li, Chaojian Li, and Yingyan (Celine) Lin
[Abstract] [Paper]
Yang Zhao, Shang Wu, Jingqun Zhang, Sixu Li, Chaojian Li, and Yingyan (Celine) Lin
[Abstract] [Paper]
Instant on-device Neural Radiance Fields (NeRFs) are in growing demand to unleash the promise of immersive AR/VR experiences, but still limited by their prohibitive training time. Our profiling analysis unveils a memory-bound bottleneck in NeRF training. To tackle this bottleneck, near-memory processing (NMP) promises to be an effective solution, but also faces various challenges due to the unique workloads of NeRFs, including random hash table lookup, random point processing sequence, and heterogeneous bottleneck steps. Therefore, we propose the first NMP framework, Instant-NeRF, dedicated to enabling instant on-device NeRF training. Experiments on eight datasets consistently validate the effectiveness of Instant-NeRF. Index Terms—Neural Radiance Field, Algorithm-Accelerator Co-Design, Near-Memory Processing, On-Device Training.
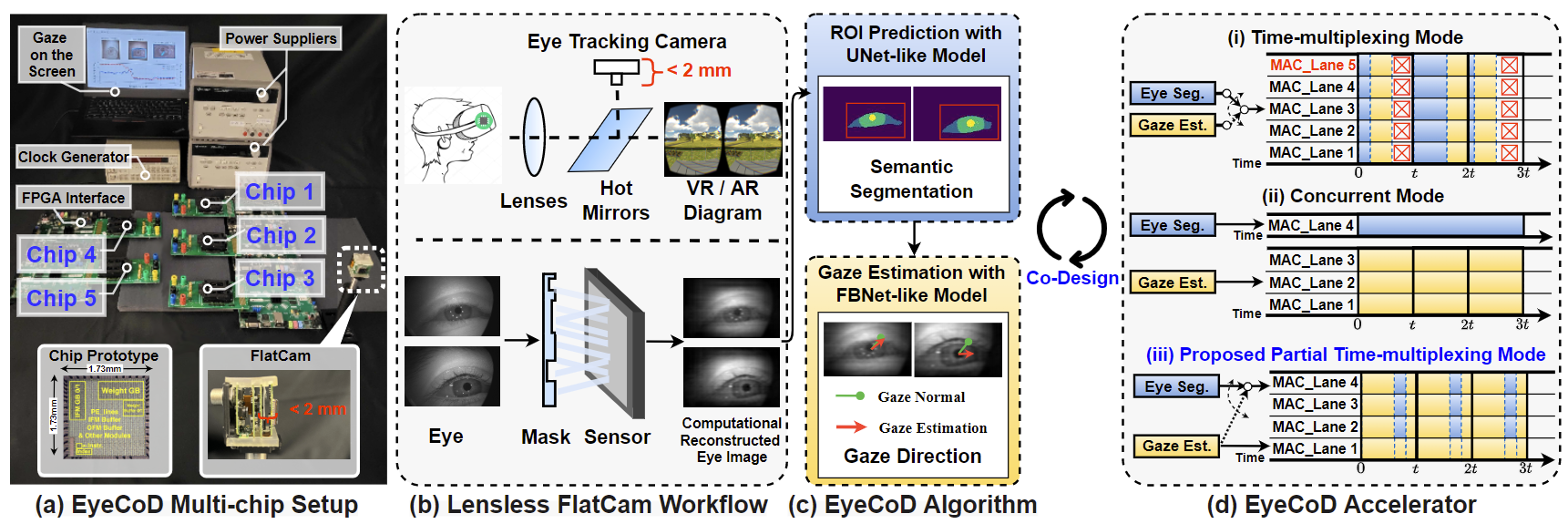
[MICRO TopPick 2023] EyeCoD: Eye Tracking System Acceleration via FlatCam-based Algorithm/Hardware Co-Design
Haoran You*, Cheng Wan*, Yang Zhao*, Zhongzhi Yu*, Yonggan Fu, Jiayi Yuan, Shang Wu, Shunyao Zhang, Yongan Zhang, Chaojian Li, Vivek Boominathan, Ashok Veeraraghavan, Ziyun Li, and Yingyan (Celine) Lin
[Abstract] [Paper] [Project Page]
Haoran You*, Cheng Wan*, Yang Zhao*, Zhongzhi Yu*, Yonggan Fu, Jiayi Yuan, Shang Wu, Shunyao Zhang, Yongan Zhang, Chaojian Li, Vivek Boominathan, Ashok Veeraraghavan, Ziyun Li, and Yingyan (Celine) Lin
[Abstract] [Paper] [Project Page]
Eye tracking has enabled many virtual and augmented reality (VR/AR) applications and desires high throughput (e.g., 240 FPS), small form-factor, and enhanced visual privacy. Existing eye tracking systems adopt bulky lens-based cameras, suffering from large form-factor and high communication cost between cameras and backend processors. Instead, we devise a lensless FlatCam-based eye tracking algorithm and hardware accelerator co-design framework dubbed EyeCoD, which is the first system to meet the high throughput requirement with smaller form-factor. On the algorithm level, EyeCoD integrates a predict-then-focus pipeline that predicts the region-of-interest (ROI) before gaze estimation. On the hardware level, EyeCoD further attaches a dedicated chip to the camera for accelerating the two machine learning models used in algorithm. Overall, the proposed EyeCoD system wins high throughput, small form-factor, and visual privacy altogether.
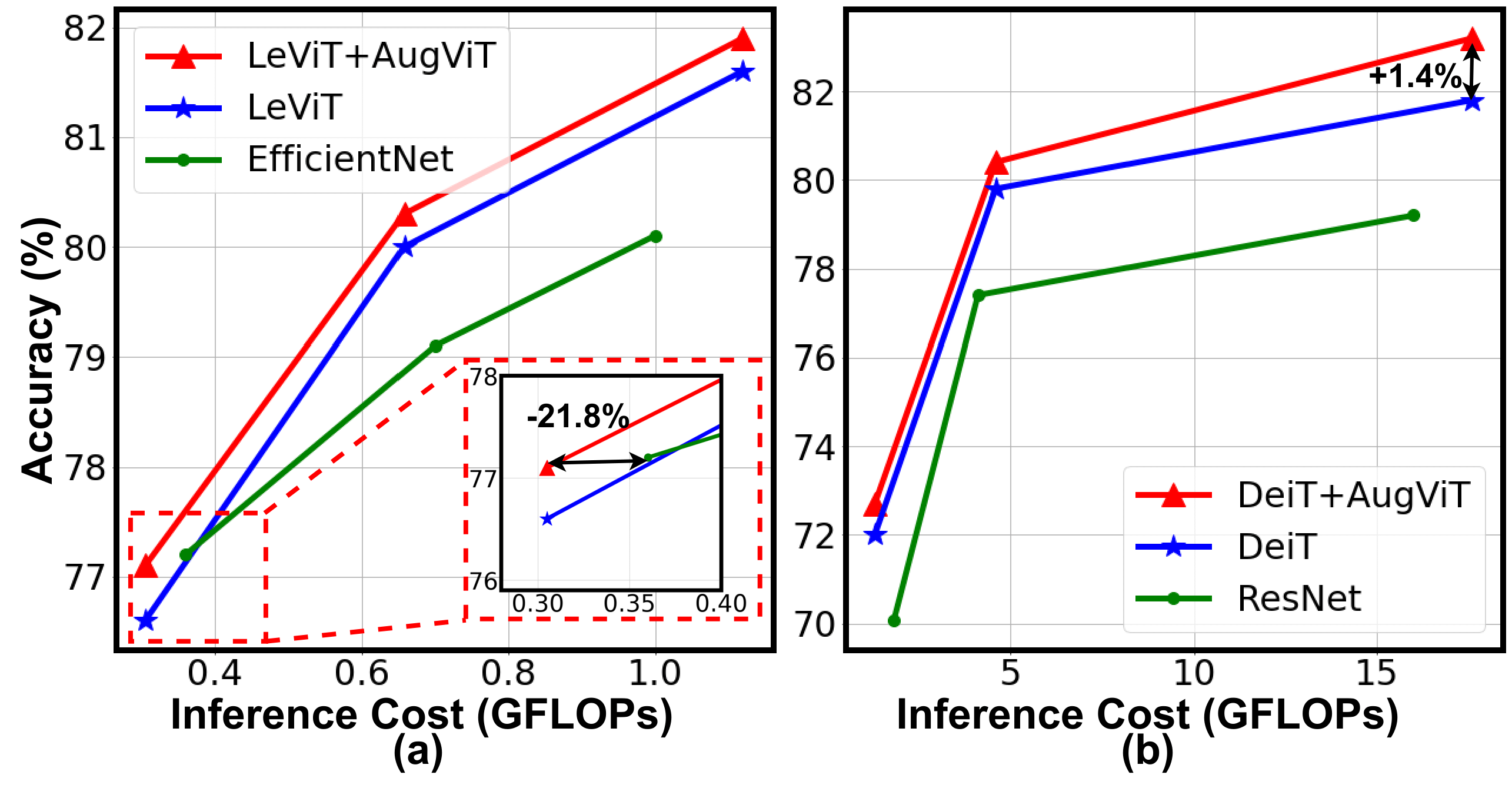
[TinyML 2023] AugViT: Improving Vision Transformer Training by Marrying Attention and Data Augmentation
Zhongzhi Yu, Yonggan Fu, Chaojian Li, and Yingyan (Celine) Lin
[Abstract]
Zhongzhi Yu, Yonggan Fu, Chaojian Li, and Yingyan (Celine) Lin
[Abstract]
Despite the impressive accuracy of large-scale vision transformers (ViTs) across various tasks, it remains a challenge for small-scale ViTs (e.g., less than 1G inference floating points operations (FLOPs) as in LeViT) to significantly outperform state-of-the-art convolution neural networks (CNNs) in terms of the accuracy-efficiency trade-off, limiting their wider application, especially on resource-constrained devices. As analyzed in recent works, selecting an effective data augmentation technique can non-trivially improve the accuracy of small-scale ViTs. However, whether existing mainstream data augmentation techniques dedicated to CNNs are optimal for ViTs is still an open question. To this end, we propose a data augmentation framework called AugViT, which is dedicated to incorporating the key component in ViTs, i.e., self-attention, into data augmentation intensity to enable ViT's outstanding accuracy across various devices. Specifically, motivated by ViT's patch-based processing pipeline, our proposed AugViT integrates (1) a dedicated scheme for mapping the attention map in ViTs to the suggested augmentation intensity for each patch, (2) a simple but effective strategy of selecting the most effective attention map within ViTs to guide the aforementioned attention-aware data argumentation, and (3) a set of patch-level augmentation techniques that matches the patch-aware processing pipeline and enables the varying of augmentation intensities in each patch. Extensive experiments and ablation studies on two datasets and ten representative ViT models validate AugViT's effectiveness in boosting ViTs' achievable accuracy, especially for small-scale ViTs, e.g., improving LeViT-128S's accuracy from 76.6\% to 77.1\%, achieving a comparable accuracy to EfficientNet-B0 with 21.8\% fewer inference FLOPs overhead on ImageNet dataset).
[HPCA 2023] ViTALiTy: Unifying Low-rank and Sparse Approximation for Vision Transformer Acceleration with a Linear Taylor Attention
Jyotikrishna Dass, Shang Wu, Huihong Shi, Chaojian Li, Zhiyan Ye, Zhongfeng Wang, and Yingyan (Celine) Lin
[Abstract] [Paper]
Jyotikrishna Dass, Shang Wu, Huihong Shi, Chaojian Li, Zhiyan Ye, Zhongfeng Wang, and Yingyan (Celine) Lin
[Abstract] [Paper]
Vision Transformer (ViT) has emerged as a competitive alternative to convolutional neural networks for various computer vision applications. Specifically, ViTs’ multi-head attention layers make it possible to embed information globally across the overall image. Nevertheless, computing and storing such attention matrices incurs a quadratic cost dependency on the number of patches, limiting its achievable efficiency and scalability and prohibiting more extensive real-world ViT applications on resource-constrained devices. Sparse attention has been shown to be a promising direction for improving hardware acceleration efficiency for NLP models. However, a systematic counterpart approach is still missing for accelerating ViT models. To close the above gap, we propose a firstof-its-kind algorithm-hardware codesigned framework, dubbed VITALITY, for boosting the inference efficiency of ViTs. Unlike sparsity-based Transformer accelerators for NLP, VITALITY unifies both low-rank and sparse components of the attention in ViTs. At the algorithm level, we approximate the dot-product softmax operation via first-order Taylor attention with row-mean centering as the low-rank component to linearize the cost of attention blocks and further boost the accuracy by incorporating a sparsity-based regularization. At the hardware level, we develop a dedicated accelerator to better leverage the resulting workload and pipeline from VITALITY’s linear Taylor attention which requires the execution of only the low-rank component, to further boost the hardware efficiency. Extensive experiments and ablation studies validate that VITALITY offers boosted endto-end efficiency (e.g., 3× faster and 3× energy-efficient) under comparable accuracy, with respect to the state-of-the-art solution.
[HPCA 2023] ViTCoD: Vision Transformer Acceleration via Dedicated Algorithm and Accelerator Co-Design
Haoran You, Zhanyi Sun, Huihong Shi, Zhongzhi Yu, Yang Zhao, Yongan Zhang, Chaojian Li, Baopu Li, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Video] [Project Page] [Slides]
Haoran You, Zhanyi Sun, Huihong Shi, Zhongzhi Yu, Yang Zhao, Yongan Zhang, Chaojian Li, Baopu Li, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Video] [Project Page] [Slides]
Vision Transformers (ViTs) have achieved state-of-the-art performance on various vision tasks. However, ViTs’ self-attention module is still arguably a major bottleneck, limiting their achievable hardware efficiency. Meanwhile, existing accelerators dedicated to NLP Transformers are not optimal for ViTs. This is because there is a large difference between ViTs and NLP Transformers: ViTs have a relatively fixed number of input tokens, whose attention maps can be pruned by up to 90% even with fixed sparse patterns; while NLP Transformers need to handle input sequences of varying numbers of tokens and rely on on-the-fly predictions of dynamic sparse attention patterns for each input to achieve a decent sparsity (e.g., >=50%). To this end, we propose a dedicated algorithm and accelerator co-design framework dubbed ViTCoD for accelerating ViTs. Specifically, on the algorithm level, ViTCoD prunes and polarizes the attention maps to have either denser or sparser fixed patterns for regularizing two levels of workloads without hurting the accuracy, largely reducing the attention computations while leaving room for alleviating the remaining dominant data movements; on top of that, we further integrate a lightweight and learnable auto-encoder module to enable trading the dominant high-cost data movements for lower-cost computations. On the hardware level, we develop a dedicated accelerator to simultaneously coordinate the enforced denser/sparser workloads and encoder/decoder engines for boosted hardware utilization. Extensive experiments and ablation studies validate that ViTCoD largely reduces the dominant data movement costs, achieving speedups of up to 235.3x, 142.9x, 86.0x, 10.1x, and 6.8x over general computing platforms CPUs, EdgeGPUs, GPUs, and prior-art Transformer accelerators SpAtten and Sanger under an attention sparsity of 90%, respectively.
pdf: https://arxiv.org/abs/2210.09573
Self-supervised learning (SSL) for rich speech representations has achieved empirical success in low-resource Automatic Speech Recognition (ASR) and other speech processing tasks, which can mitigate the necessity of a large amount of transcribed speech and thus has driven a growing demand for on-device ASR and other speech processing. However, advanced speech SSL models have become increasingly large, which contradicts the limited on-device resources. This gap could be more severe in multilingual/multitask scenarios requiring simultaneously recognizing multiple languages or executing multiple speech processing tasks. Additionally, strongly overparameterized speech SSL models tend to suffer from overfitting when being finetuned on low-resource speech corpus. This work aims to enhance the practical usage of speech SSL models towards a win-win in both enhanced efficiency and alleviated overfitting via our proposed S-Router framework, which for the first time discovers that simply discarding no more than 10% of model weights via only finetuning model connections of speech SSL models can achieve better accuracy over standard weight finetuning on downstream speech processing tasks. More importantly, S-Router can serve as an all-in-one technique to enable (1) a new finetuning scheme, (2) an efficient multilingual/multitask solution, (3) a state-of-the-art pruning technique, and (4) a new tool to quantitatively analyze the learned speech representation.
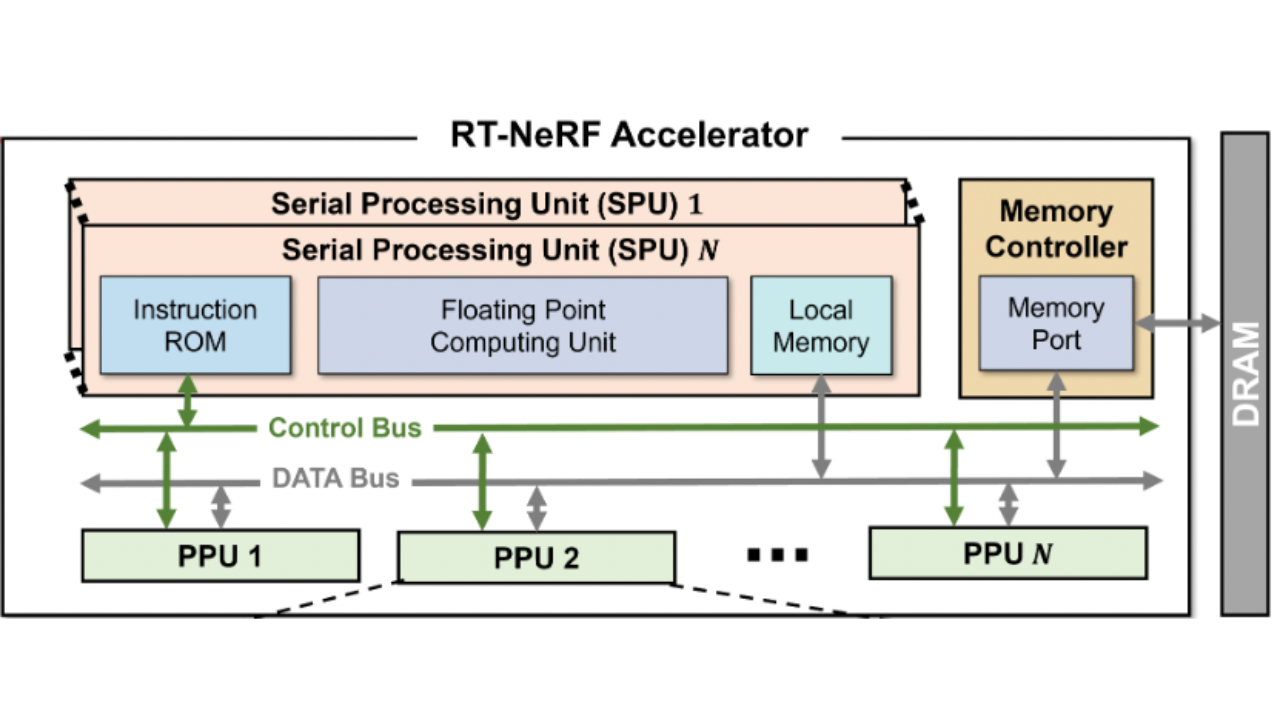
[ICCAD 2022]
RT-NeRF: Real-Time On-Device Neural Radiance Fields Towards Immersive AR/VR Rendering
Chaojian Li, Sixu Li, Yang Zhao, Wenbo Zhu, and Yingyan (Celine) Lin
[Abstract] [Paper] [Project Page] [Video]
Chaojian Li, Sixu Li, Yang Zhao, Wenbo Zhu, and Yingyan (Celine) Lin
[Abstract] [Paper] [Project Page] [Video]
Neural Radiance Field (NeRF) based rendering has attracted growing attention thanks to its state-of-the-art (SOTA) rendering quality and wide applications in Augmented and Virtual Reality (AR/VR). However, immersive real-time (> 30 FPS) NeRF based rendering enabled interactions are still limited due to the low achievable throughput on AR/VR devices. To this end, we first profile SOTA efficient NeRF al- gorithms on commercial devices and identify two primary causes of the aforementioned inefficiency: (1) the uniform point sampling and (2) the dense accesses and computations of the required embeddings in NeRF. Furthermore, we propose RT-NeRF, which to the best of our knowledge is the first algorithm-hardware co-design acceleration of NeRF. Specifically, on the algorithm level, RT-NeRF integrates an efficient rendering pipeline for largely alleviating the inefficiency due to the commonly adopted uniform point sampling method in NeRF by directly computing the geometry of pre-existing points. Additionally, RT-NeRF leverages a coarse-grained view-dependent computing ordering scheme for eliminating the (unnecessary) pro- cessing of invisible points. On the hardware level, our proposed RT-NeRF accelerator (1) adopts a hybrid encoding scheme to adap- tively switch between a bitmap- or coordinate-based sparsity encoding format for NeRF's sparse embeddings, aiming to maximize the storage savings and thus reduce the required DRAM accesses while supporting efficient NeRF decoding; and (2) integrates both a high-density sparse search unit and a dual-purpose bi-direction adder & search tree to coordinate the two aforementioned encod- ing formats. Extensive experiments on eight datasets consistently validate the effectiveness of RT-NeRF, achieving a large throughput improvement (e.g., 9.7x ~3,201x) while maintaining the rendering quality as compared with SOTA efficient NeRF solutions.
Multiplication is arguably the most cost-dominant operation in modern deep neural networks (DNNs), limiting their achievable efficiency and thus more extensive deployment in resource-constrained applications. To tackle this limitation, pioneering works have developed handcrafted multiplication-free DNNs, which require expert knowledge and time-consuming manual iteration, calling for fast development tools. To this end, we propose a Neural Architecture Search and Acceleration framework dubbed NASA, which enables automated multiplication-reduced DNN development and integrates a dedicated multiplication-reduced accelerator for boosting DNNs' achievable efficiency. Specifically, NASA adopts neural architecture search (NAS) spaces that augment the state-of-the-art one with hardware inspired multiplication-free operators, such as shift and adder, armed with a novel progressive pretrain strategy (PGP) together with customized training recipes to automatically search for optimal multiplication-reduced DNNs; On top of that, NASA further develops a dedicated accelerator, which advocates a chunk-based template and auto-mapper dedicated for NASA-NAS resulting DNNs to better leverage their algorithmic properties for boosting hardware efficiency. Experimental results and ablation studies consistently validate the advantages of NASA's algorithm-hardware co-design framework in terms of achievable accuracy and efficiency tradeoffs.
Graph Convolutional Networks (GCNs) have emerged as the state-of-the-art method for graph-based learning tasks. However, training GCNs at scale is still challenging, hindering both the exploration of more sophisticated GCN architectures and their applications to real-world large graphs. While it might be natural to consider graph partition and distributed training for tackling this challenge, this direction has only been slightly scratched the surface in the previous works due to the limitations of existing designs. In this work, we first analyze why distributed GCN training is ineffective and identify the underlying cause to be the excessive number of boundary nodes of each partitioned subgraph, which easily explodes the memory and communication costs for GCN training. Furthermore, we propose a simple yet effective method dubbed BNS-GCN that adopts random Boundary-Node-Sampling to enable efficient and scalable distributed GCN training. Experiments and ablation studies consistently validate the effectiveness of BNS-GCN, e.g., boosting the throughput by up to 16.2x and reducing the memory usage by up to 58%, while maintaining a full-graph accuracy. Furthermore, both theoretical and empirical analysis show that BNS-GCN enjoys a better convergence than existing sampling-based methods. We believe that our BNS-GCN has opened up a new paradigm for enabling GCN training at scale. The code is available at https://github.com/RICE-EIC/BNS-GCN.
Neural architecture search (NAS) has demonstrated amazing success in searching for efficient deep neural networks (DNNs) from a given supernet. In parallel, the lottery ticket hypothesis has shown that DNNs contain small subnetworks that can be trained from scratch to achieve a comparable or higher accuracy than original DNNs. As such, it is currently a common practice to develop efficient DNNs via a pipeline of first search and then prune. Nevertheless, doing so often requires a search-train-prune-retrain process and thus prohibitive computational cost. In this paper, we discover for the first time that both efficient DNNs and their lottery subnetworks (i.e., lottery tickets) can be directly identified from a supernet, which we term as SuperTickets, via a two-in-one training scheme with jointly architecture searching and parameter pruning. Moreover, we develop a progressive and unified SuperTickets identification strategy that allows the connectivity of subnetworks to change during supernet training, achieving better accuracy and efficiency trade-offs than conventional sparse training. Finally, we evaluate whether such identified SuperTickets drawn from one task can transfer well to other tasks, validating their potential of handling multiple tasks simultaneously. Extensive experiments and ablation studies on three tasks and four benchmark datasets validate that our proposed SuperTickets achieve boosted accuracy and efficiency trade-offs than both typical NAS and pruning pipelines, regardless of having retraining or not. Codes and pretrained models are available at https://github.com/RICE-EIC/SuperTickets.
[ICML 2022]
DepthShrinker: A New Compression Paradigm Towards Boosting Real-Hardware Efficiency of Compact Neural Networks
Yonggan Fu, Haichuan Yang, Jiayi Yuan, Meng Li, Cheng Wan, Raghuraman Krishnamoorthi, Vikas Chandra, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Video] [Project Page]
Yonggan Fu, Haichuan Yang, Jiayi Yuan, Meng Li, Cheng Wan, Raghuraman Krishnamoorthi, Vikas Chandra, and Yingyan (Celine) Lin
[Abstract] [Paper] [Code] [Video] [Project Page]
Efficient deep neural network (DNN) models equipped with compact operators (e.g., depthwise convolutions) have shown great potential in reducing DNNs' theoretical complexity (e.g., the total number of weights/operations) while maintaining a decent model accuracy. However, existing efficient DNNs are still limited in fulfilling their promise in boosting real-hardware efficiency, due to their commonly adopted compact operators' low hardware utilization. In this work, we open up a new compression paradigm for developing real-hardware efficient DNNs, leading to boosted hardware efficiency while maintaining model accuracy. Interestingly, we observe that while some DNN layers' activation functions help DNNs' training optimization and achievable accuracy, they can be properly removed after training without compromising the model accuracy. Inspired by this observation, we propose a framework dubbed DepthShrinker, which develops hardware-friendly compact networks via shrinking the basic building blocks of existing efficient DNNs that feature irregular computation patterns into dense ones with much improved hardware utilization and thus real-hardware efficiency. Excitingly, our DepthShrinker framework delivers hardware-friendly compact networks that outperform both state-of-the-art efficient DNNs and compression techniques.
Neural networks (NNs) with intensive multiplications (e.g., convolutions and transformers) are capable yet power hungry, impeding their more extensive deployment into resource-constrained devices.
As such, multiplication-free networks, which follow a common practice in energy-efficient hardware implementation to parameterize NNs with more efficient operators (e.g., bitwise shifts and additions), have gained growing attention. However, multiplication-free networks usually under-perform their vanilla counterparts in terms of the achieved accuracy. To this end, this work advocates hybrid NNs that consist of both powerful yet costly multiplications and efficient yet less powerful operators for marrying the best of both worlds, and proposes ShiftAddNAS, which can automatically search for more accurate and more efficient NNs. Our ShiftAddNAS highlights two enablers. Specifically, it integrates (1) the first hybrid search space that incorporates both multiplication-based and multiplication-free operators for facilitating the development of both accurate and efficient hybrid NNs; and (2) a novel weight sharing strategy that enables effective weight sharing among different operators that follow heterogeneous distributions (e.g., Gaussian for convolutions vs. Laplacian for add operators) and simultaneously leads to a largely reduced supernet size and much better searched networks.
Extensive experiments and ablation studies on various models, datasets, and tasks consistently validate the efficacy of ShiftAddNAS, e.g., achieving up to a +7.7% higher accuracy or a +4.9 better BLEU score compared to state-of-the-art NN, while leading to up to 93% or 69% energy and latency savings, respectively.
Contrastive learning learns visual representations by enforcing feature consistency under different augmented views. In this work, we explore contrastive learning from a new perspective. Interestingly, we find that quantization, when properly engineered, can enhance the effectiveness of contrastive learning. To this end, we propose a novel contrastive learning framework, dubbed Contrastive Quant, to encourage the feature consistency under both differently augmented inputs via various data transformations and differently augmented weights/activations via various quantization levels. Extensive experiments, built on top of two state-of-the-art contrastive learning methods SimCLR and BYOL, show that Contrastive Quant consistently improves the learned visual representation.
[VLSI 2022]
e-G2C: A 0.14-to-8.31 μJ/Inference NN-based Processor with Continuous On-chip Adaptation for Anomaly Detection and ECG Conversion from EGM
Yang Zhao, Yongan Zhang, Yonggan Fu, Xu Ouyang, Cheng Wan, Shang Wu, Anton Banta, Mathews M. John, Allison Post, Mehdi Razavi, Joseph Cavallaro, Behnaam Aazhang, and Yingyan (Celine) Lin
[Abstract] [Paper] [arXiv] [doi]
Yang Zhao, Yongan Zhang, Yonggan Fu, Xu Ouyang, Cheng Wan, Shang Wu, Anton Banta, Mathews M. John, Allison Post, Mehdi Razavi, Joseph Cavallaro, Behnaam Aazhang, and Yingyan (Celine) Lin
[Abstract] [Paper] [arXiv] [doi]
This work presents the first silicon-validated dedicated EGM-to-ECG (G2C) processor, dubbed e-G2C, featuring continuous lightweight anomaly detection, event-driven coarse/precise conversion, and on-chip adaptation. e-G2C utilizes neural network (NN) based G2C conversion and integrates 1) an architecture supporting anomaly detection and coarse/precise conversion via time multiplexing to balance the effectiveness and power, 2) an algorithm-hardware codesigned vector-wise sparsity resulting in a 1.6-1.7× speedup, 3) hybrid dataflows for enhancing near 100% utilization for normal/depth-wise(DW)/point-wise(PW) convolutions (Convs), and 4) an on-chip detection threshold adaptation engine for continuous effectiveness. The achieved 0.14-8.31 μJ/inference energy efficiency outperforms prior arts under similar complexity, promising real-time detection/conversion and possibly life-critical interventions.
[VLSI 2022]
i-FlatCam: A 253 FPS, 91.49 µJ/Frame Ultra-Compact Intelligent Lensless Camera System for Real-Time and Efficient Eye Tracking in VR/AR
Yang Zhao, Ziyun Li, Yonggan Fu, Yongan Zhang, Chaojian Li, Cheng Wan, Haoran You, Shang Wu, Xu Ouyang, Vivek Boominathan, Ashok Veeraraghavan, and Yingyan (Celine) Lin
[Abstract] [Paper] [arXiv] [doi] [Video]
Yang Zhao, Ziyun Li, Yonggan Fu, Yongan Zhang, Chaojian Li, Cheng Wan, Haoran You, Shang Wu, Xu Ouyang, Vivek Boominathan, Ashok Veeraraghavan, and Yingyan (Celine) Lin
[Abstract] [Paper] [arXiv] [doi] [Video]
We present a first-of-its-kind ultra-compact intelligent camera system, dubbed i-FlatCam, including a lensless camera with a computational (Comp.) chip. It highlights (1) a predict-then-focus eye tracking pipeline for boosted efficiency without compromising the accuracy, (2) a unified compression scheme for single-chip processing and improved frame rate per second (FPS), and (3) dedicated intra-channel reuse design for depth-wise convolutional layers (DW-CONV) to increase utilization. i-FlatCam demonstrates the first eye tracking pipeline with a lensless camera and achieves 3.16 degrees of accuracy, 253 FPS, 91.49 µJ/Frame, and 6.7mmx8.9mmx1.2mm camera form factor, paving the way for next-generation Augmented Reality (AR) and Virtual Reality (VR) devices.
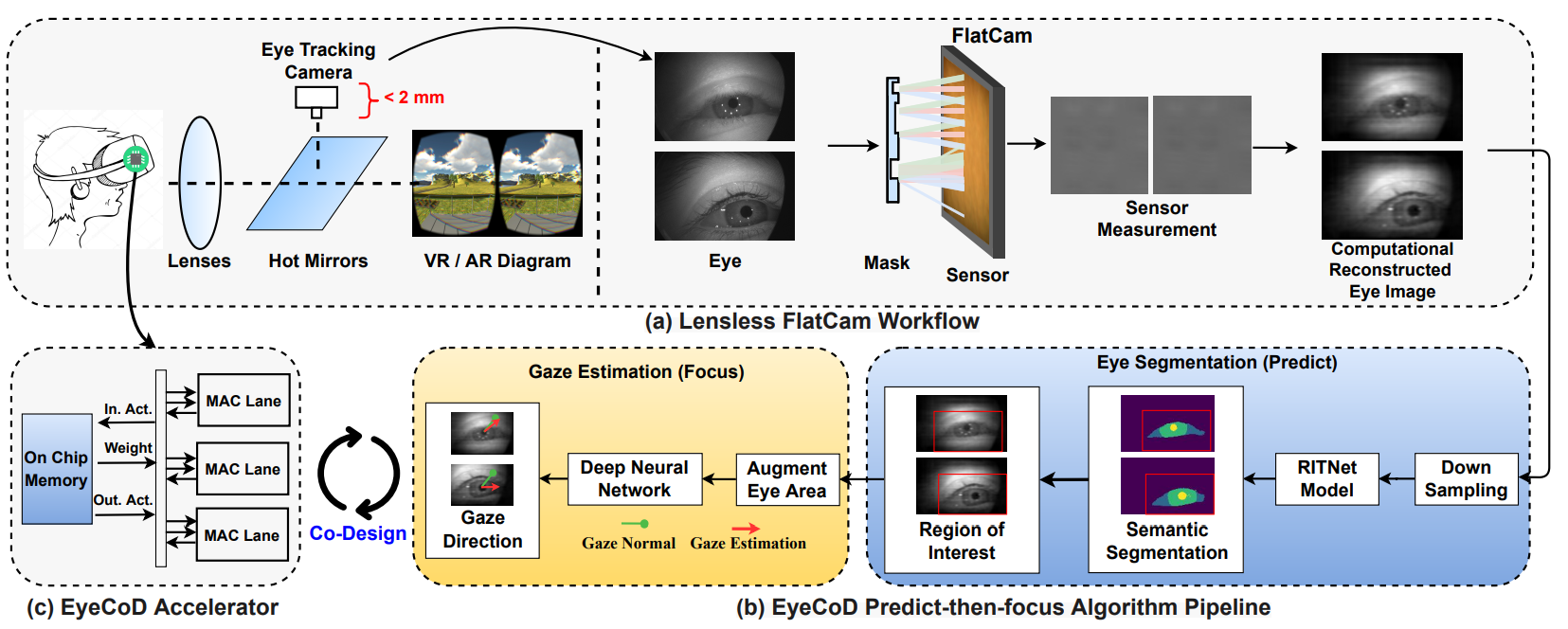
[ISCA 2022]
EyeCoD: Eye Tracking System Acceleration via FlatCam-Based Algorithm and Accelerator Co-Design
Haoran You, Yang Zhao, Zhongzhi Yu, Cheng Wan, Yonggan Fu, Jiayi Yuan, Shang Wu, Shunyao Zhang, Yongan Zhang, Chaojian Li, Vivek Boominathan, Ashok Veeraraghavan, Ziyun Li, and Yingyan (Celine) Lin
[Abstract] [Paper] [arXiv] [Video] [Project Page] [Slides]
Haoran You, Yang Zhao, Zhongzhi Yu, Cheng Wan, Yonggan Fu, Jiayi Yuan, Shang Wu, Shunyao Zhang, Yongan Zhang, Chaojian Li, Vivek Boominathan, Ashok Veeraraghavan, Ziyun Li, and Yingyan (Celine) Lin
[Abstract] [Paper] [arXiv] [Video] [Project Page] [Slides]
Eye tracking has become an essential human-machine interaction modality for providing immersive experience in numerous virtual and augmented reality (VR/AR) applications desiring high throughput, e.g., 240 FPS, as well as small-form and enhanced visual privacy. However, existing eye tracking systems are still limited by their: (1) large form-factor largely due to the adopted bulky lens-based cameras; (2) high communication cost required between the camera and backend processor; and (3) potentially concerned low visual privacy, thus prohibiting their more extensive applications. To this end, we propose, develop, and validate a lensless FlatCam-based eye tracking algorithm and accelerator co-design framework dubbed EyeCoD to enable eye tracking systems with a much reduced form-factor and boosted system efficiency without sacrificing tracking accuracy, paving the way for next-generation eye tracking solutions. On the system level, we advocate the use of lensless FlatCams instead of lens-based cameras to facilitate the small form-factor need in mobile eye tracking systems, which also leaves rooms for a dedicated sensing-processor co-design to reduce the required camera-processor communication latency. On the algorithm level, EyeCoD integrates a predict-then-focus pipeline that first predicts the region-of-interest (ROI) via segmentation and then only focuses on the ROI parts to estimate gaze directions for reduced redundant computations and data movements. On the hardware level, we further develop a dedicated accelerator that (1) integrates a novel workload orchestration between the aforementioned segmentation and gaze estimation models, (2) leverages intra-channel reuse opportunities for depth-wise layers, (3) utilizes input feature-wise partition to save activation memory size, and (4) develops a sequential-write-parallel-read input buffer to release activation global buffer bandwidth requirement. On-silicon measurement and extensive experiments validate that our EyeCoD consistently reduces both communication and computation costs, leading to an overall system speedup of 10.95x, 3.21x, and 12.85x over general computing platforms CPUs, GPUs, and a prior-art eye tracking processor CIS-GEP, respectively, while maintaining the tracking accuracy.

Graph Convolutional Networks (GCNs) is the state-of-the-art method for learning graph-structured data, and training large-scale GCNs requires distributed training across multiple accelerators such that each accelerator is able to hold a partitioned subgraph. However, distributed GCN training incurs prohibitive overhead of communicating node features and feature gradients among partitions for every GCN layer during each training iteration, limiting the achievable training efficiency and model scalability. To this end, we propose PipeGCN, a simple yet effective scheme that hides the communication overhead by pipelining inter-partition communication with intra-partition computation. It is non-trivial to pipeline for efficient GCN training, as communicated node features/gradients will become stale and thus can harm the convergence, negating the pipeline benefit. Notably, little is known regarding the convergence rate of GCN training with both stale features and stale feature gradients. This work not only provides a theoretical convergence analysis but also finds the convergence rate of PipeGCN to be close to that of the vanilla distributed GCN training without any staleness. Furthermore, we develop a smoothing method to further improve PipeGCN's convergence. Extensive experiments show that PipeGCN can largely boost the training throughput (1.7×~28.5×) while achieving the same accuracy as its vanilla counterpart and existing full-graph training methods. The code is available at https://github.com/RICE-EIC/PipeGCN.

Vision transformers (ViTs) have recently set off a new wave in neural architecture design thanks to their record-breaking performance in various vision tasks. In parallel, to fulfill the goal of deploying ViTs into real-world vision applications, their robustness against potential malicious attacks has gained increasing attention. In particular, recent works show that ViTs are more robust against adversarial attacks as compared with convolutional neural networks (CNNs), and conjecture that this is because ViTs focus more on capturing global interactions among different input/feature patches, leading to their improved robustness to the local perturbations imposed by adversarial attacks. In this work, we ask an intriguing question: ``Under what kinds of perturbations do ViTs become weaker learners compared to CNNs"? Driven by this question, we conduct a comprehensive examination on the robustness of both ViTs and CNNs under various existing adversarial attacks to understand the underlying reason for their robustness. Based on the insights drawn, we have developed a dedicated attack framework, dubbed Patch-Fool, that fools the self-attention mechanism by attacking the basic component (i.e., a single patch) participating in self-attention calculations with a series of attention-aware optimization techniques. Based on extensive experiments, we find that ViTs are weaker learners compared with CNNs against our Patch-Fool and the results from Sparse Patch-Fool, a sparse variant of our Patch-Fool, indicate that the perturbation density on each patch seems to be the key factor that influences the robustness ranking between ViTs and CNNs. It is expected that our work will shed light on both future architecture designs and training schemes for robustifying ViTs towards their real-world deployment.
Graph Convolutional Networks (GCNs) have emerged as the state-of-the-art graph learning model. However, it remains notoriously challenging to inference GCNs over large graph datasets, limiting their application to large real-world graphs and hindering the exploration of deeper and more sophisticated GCN graphs. This is because real-world graphs can be extremely large and sparse. Furthermore, the node degree of GCNs tends to follow the power-law distribution and therefore have highly irregular adjacency matrices, resulting in prohibitive inefficiencies in both data processing and movement and thus substantially limiting the achievable GCN acceleration efficiency. To this end, this paper proposes the first GCN algorithm and accelerator Co-Design framework dubbed GCoD which can largely alleviate the aforementioned GCN irregularity and boost GCNs' inference efficiency. Specifically, on the algorithm level, GCoD integrates a divide and conquer GCN training strategy that polarizes the graphs to be either denser or sparser in local neighborhoods without compromising the model accuracy, resulting in graph adjacency matrices that (mostly) have merely two levels of workload and enjoys largely enhanced regularity and thus ease of acceleration. On the hardware level, we further develop a dedicated two-pronged accelerator with a separated engine to process each of the aforementioned workloads, further boosting the overall utilization and acceleration efficiency. Extensive experiments and ablation studies validate that our GCoD consistently reduces off-chip accesses, leading to speedups over CPUs, GPUs, prior-art GCN accelerators HyGCN and AWB-GCN of 15286x, 294x, 7.8x, and 2.5x, respectively, while maintaining or even improving the task accuracy. Additionally, we visualize GCoD trained graph adjacency matrices to better understand its advantages.
Graph Convolutional Networks (GCNs) have emerged as the state-of-the-art deep learning model for representation learning on graphs. However, it remains notoriously challenging to train and inference GCNs over large graph datasets, limiting their application to large real-world graphs and hindering the exploration of deeper and more sophisticated GCN graphs. This is because as the graph size grows, the sheer number of node features and the large adjacency matrix can easily explode the required memory and data movements. To tackle the aforementioned challenges, we explore the possibility of drawing lottery tickets when sparsifying GCN graphs, i.e., subgraphs that largely shrink the adjacency matrix yet are capable of achieving accuracy comparable to or even better than their full graphs. Specifically, we for the first time discover the existence of graph early-bird (GEB) tickets that emerge at the very early stage when sparsifying GCN graphs, and propose a simple yet effective detector to automatically identify the emergence of such GEB tickets. Furthermore, we advocate graph-model co-optimization and develop a generic efficient GCN early-bird training framework dubbed GEBT that can significantly boost the efficiency of GCN training by (1) drawing joint early-bird tickets between the GCN graphs and models and (2) enabling simultaneously sparsification of both the GCN graphs and models. Experiments on various GCN models and datasets consistently validate our GEB finding and the effectiveness of our GEBT, e.g., our GEBT achieves up to 80.2% ~ 85.6% and 84.6% ~ 87.5% savings of GCN training and inference costs while offering a comparable or even better accuracy as compared to state-of-the-art methods. Furthermore, our GEBT is found to scale up to deep GCNs.
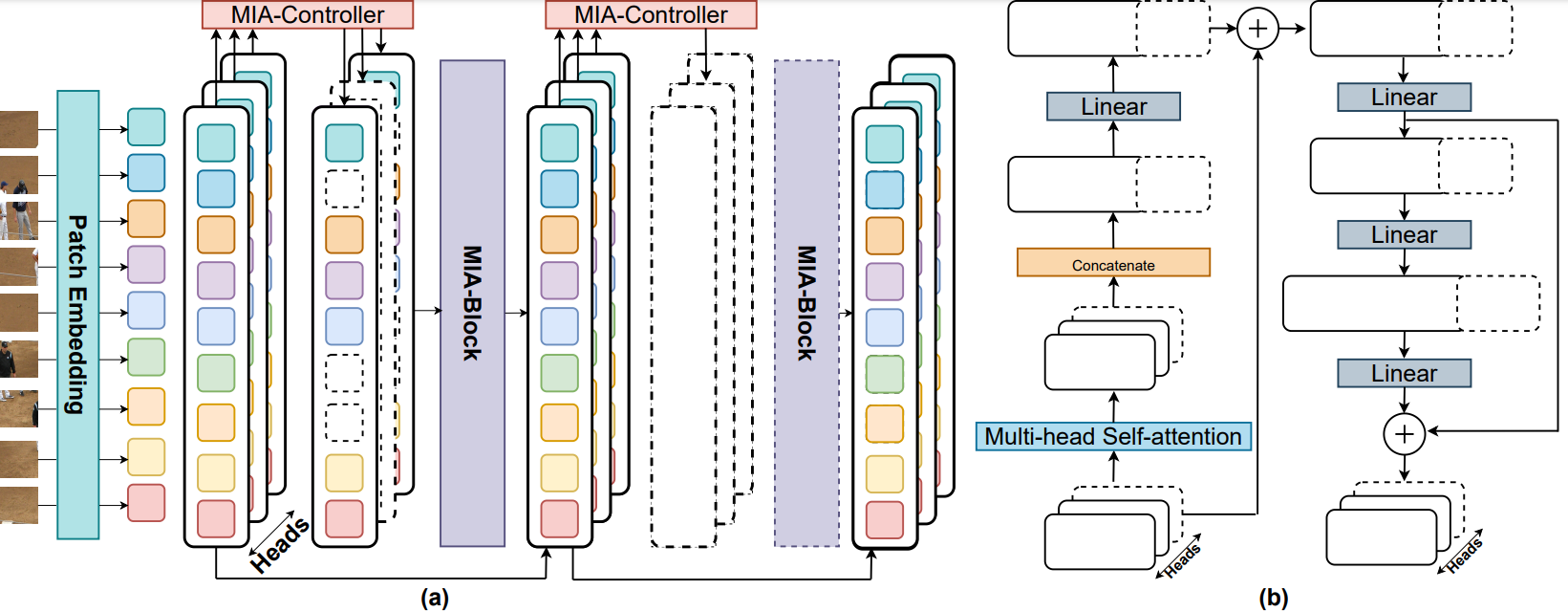
Vision transformers have recently demonstrated great success in various computer vision tasks, motivating a tremendously increased interest in their deployment into many real-world IoT applications. However, powerful ViTs are often too computationally expensive to be fitted onto real-world resource-constrained platforms, due to (1) their quadratically increased complexity with the number of input tokens and (2) their overparameterized self-attention heads and model depth. In parallel, different images are of varied complexity and their different regions can contain various levels of visual information, e.g., a sky background is not as informative as a foreground object in object classification tasks, indicating that treating those regions equally in terms of model complexity is unnecessary while such opportunities for trimming down ViTs’ complexity have not been fully exploited. To this end, we propose a Multi-grained Input-Adaptive Vision Transformer framework dubbed MIA-Former that can input-adaptively adjust the structure of ViTs at three coarse-to-fine-grained granularities (i.e., model depth and the number of model heads/tokens). In particular, our MIA-Former adopts a low-cost network trained with a hybrid supervised and reinforcement learning method to skip the unnecessary layers, heads, and tokens in an input adaptive manner, reducing the overall computational cost. Furthermore, an interesting side effect of our MIA-Former is that its resulting ViTs are naturally equipped with improved robustness against adversarial attacks over their static counterparts, because MIA-Former’s multi-grained dynamic control improves the model diversity similar to the effect of ensemble and thus increases the difficulty of adversarial attacks against all its sub-models. Extensive experiments and ablation studies validate that the
proposed MIA-Former framework can (1) effectively allocate adaptive computation budgets to the difficulty of input images, achieving state-of-the-art (SOTA) accuracy-efficiency trade-offs, e.g., up to 16.5% computation savings with the same or even a higher accuracy compared with the SOTA dynamic transformer models, and (2) boost ViTs’ robustness accuracy under various adversarial attacks over their vanilla counterparts by 2.4% and 3.0%, respectively.
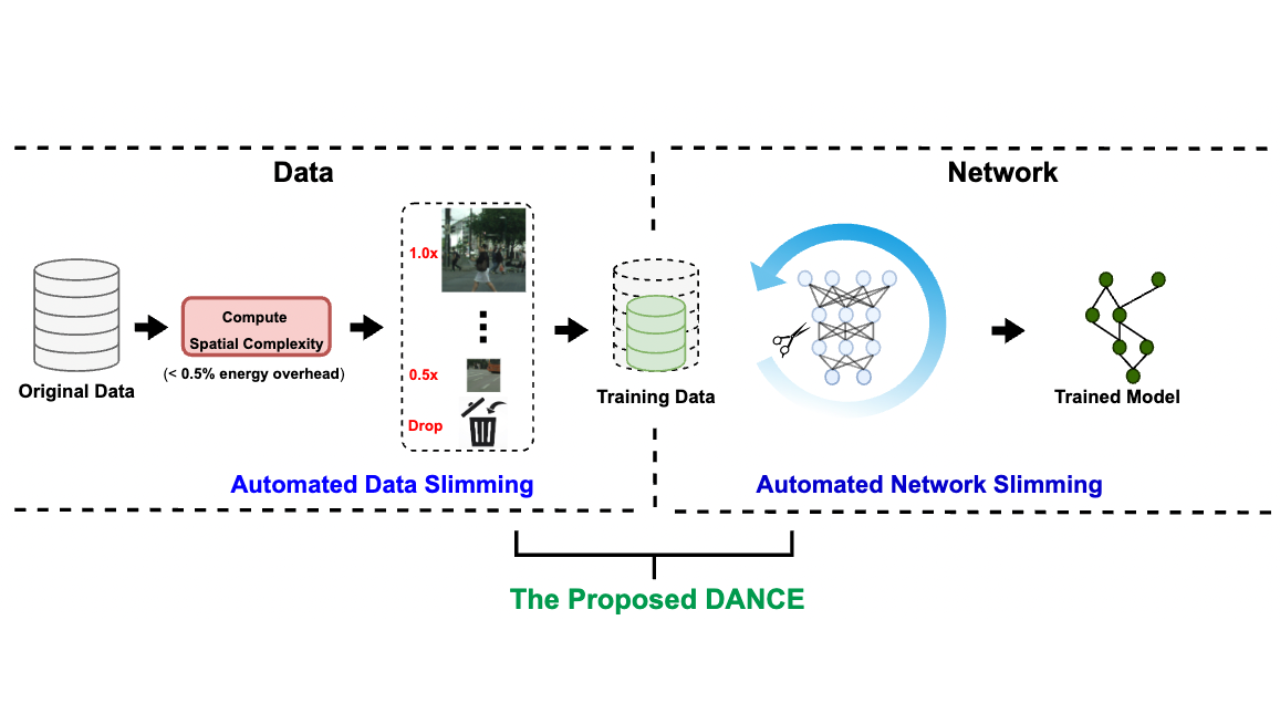
Semantic segmentation for scene understanding is nowadays widely demanded, raising significant challenges for the algorithm efficiency, especially its applications on resource-limited platforms. Current segmentation models are trained and evaluated on massive highresolution scene images (“data level”) and suffer from the expensive computation arising from the required multi-scale aggregation (“network level”). In both folds, the computational and energy costs in training and inference are notable due to the often desired large input resolutions and heavy computational burden of segmentation models. To this end, we propose DANCE, general automated DAtaNetwork Co-optimization for Efficient segmentation model training and inference. Distinct from existing efficient segmentation approaches that focus merely on light-weight network design, DANCE distinguishes itself as an automated simultaneous data-network co-optimization via both input data manipulation and network architecture slimming. Specifically, DANCE integrates automated data slimming which adaptively downsamples/drops input images and controls their corresponding contribution to the training loss guided by the images’ spatial complexity. Such a downsampling operation, in addition to slimming down the cost associated with the input size directly, also shrinks the dynamic range of input object and context scales, therefore motivating us to also adaptively slim the network to match the downsampled data. Extensive experiments and ablating studies (on four SOTA segmentation models with three popular segmentation datasets under two training settings) demonstrate that DANCE can achieve “all-win” towards efficient segmentation (reduced training cost, less expensive inference, and better mean Intersection-over-Union (mIoU)). Specifically, DANCE can reduce ↓25% - ↓77% energy consumption in training, ↓31% - ↓56% in inference, while boosting the mIoU by ↓0.71% - ↑ 13.34%.
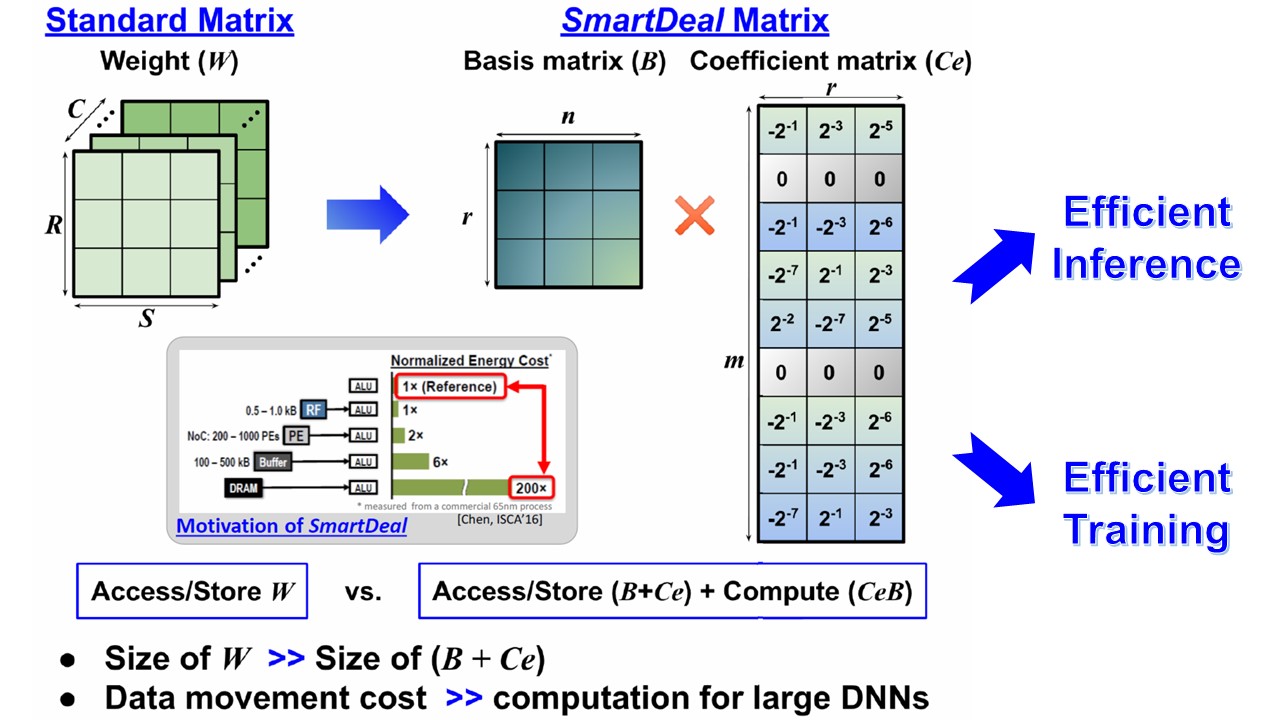
The record-breaking performance of deep neural networks (DNNs) comes with heavy parameter budgets, which leads to external dynamic random-access memory (DRAM) for storage. The prohibitive energy of DRAM accesses makes it non-trivial for DNN deployment on resource-constrained devices, calling for minimizing the movements of weights and data in order to improve the energy efficiency. Driven by this critical bottleneck, we present SmartDeal, a hardware-friendly algorithm framework to trade higher-cost memory storage/access for lower cost computation, in order to aggressively boost the storage and energy efficiency, for both DNN inference and training.
The core technique of SmartDeal is a novel DNN weight matrix decomposition framework with respective structural constraints on each matrix factor, carefully crafted to unleash the hardware aware efficiency potential. Specifically, we decompose each weight tensor as the product of a small basis matrix and a large structurally sparse coefficient matrix whose non-zero elements are readily quantized to power-of-2. The resulting sparse and readily quantized DNNs enjoy greatly reduced energy consumption in data movement as well as weight storage, while incurring minimal overhead to recover the original weights thanks to the required sparse bit-operations and cost favorable computations. Beyond inference, we take another leap to embrace energy-efficient training, by introducing several customized techniques to address the unique roadblocks arising in training while preserving the SmartDeal structures. We also design a dedicated hardware accelerator to fully utilize the new weight structure to improve the real energy efficiency and latency performance.
We conduct experiments on both vision and language tasks, with nine models, four datasets, and three settings (inference-only, adaptation, and fine-tuning). Our extensive results show that: 1) being applied to inference, SmartDeal achieves up to 2.44× improvement in energy efficiency as evaluated via real hardware implementations; 2) being applied to training, SmartDeal can lead to 10.56× and 4.48× reduction in the storage and the training energy cost, respectively, with usually negligible accuracy loss, compared to state-of-the-art training baselines. Our source codes are available at: https://github.com/VITA-Group/SmartDeal
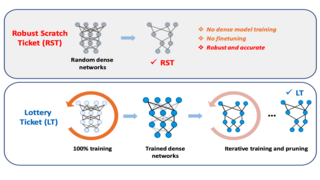
Deep Neural Networks (DNNs) are known to be vulnerable to adversarial attacks, i.e., an imperceptible perturbation to the input can mislead DNNs trained on clean images into making erroneous predictions. To tackle this, adversarial training is currently the most effective defense method, by augmenting the training set with adversarial samples generated on the fly. Interestingly, we discover for the first time that there exist subnetworks with inborn robustness, matching or surpassing the robust accuracy of the adversarially trained networks with comparable model sizes, within randomly initialized networks without any model training, indicating that adversarial training on model weights is not indispensable towards adversarial robustness. We name such subnetworks Robust Scratch Tickets (RSTs), which are also by nature efficient. Distinct from the popular lottery ticket hypothesis, neither the original dense networks nor the identified RSTs need to be trained. To validate and understand this fascinating finding, we further conduct extensive experiments to study the existence and properties of RSTs under different models, datasets, sparsity patterns, and attacks, drawing insights regarding the relationship between DNNs’ robustness and their initialization/overparameterization. Furthermore, we identify the poor adversarial transferability between RSTs of different sparsity ratios drawn from the same randomly initialized dense network, and propose a Random RST Switch (R2S) technique, which randomly switches between different RSTs, as a novel defense method built on top of RSTs. We believe our findings about RSTs have opened up a new perspective to study model robustness and extend the lottery ticket hypothesis.
The emergence of the Internet-of-Things (IoT) sheds light on applying the machine teaching (MT) algorithms for online personalized education on home devices. This direction becomes more promising during the COVID-19 pandemic when in-person education becomes infeasible. However, as one of the most influential and practical MT paradigms, iterative machine teaching (IMT) is prohibited on IoT devices due to its inefficient and unscalable algorithms. IMT is a paradigm where a teacher feeds examples iteratively and intelligently based on the learner's current status. In each iteration, current IMT algorithms greedily traverse the whole training set to find the sample for the learner, which is computationally expensive in practice. We propose a novel teaching framework, Locality Sensitive Teaching (LST), based on locality sensitive sampling, to overcome these challenges. LST has provable near-constant time complexity, which is exponentially better than the existing baseline. With at most 425.12x speedups and 99.76% energy savings over IMT, LST is the first algorithm that enables energy and time efficient machine teaching on IoT devices. Owing to LST's substantial efficiency and scalability, it is readily applicable in real-world education scenarios.
The recent breakthroughs and prohibitive complexity of Deep Neural Networks (DNNs) have excited extensive interest in domain-specific DNN accelerators, among which optical DNN accelerators are particularly promising thanks to their unprecedented potential of achieving superior performance-per-watt. However, the development of optical DNN accelerators is much slower than that of electrical DNN accelerators. One key challenge is that while many techniques have been developed to facilitate the development of electrical DNN accelerators, techniques that support or expedite optical DNN accelerator design remain much less explored, limiting both the achievable performance and the innovation development of optical DNN accelerators. To this end, we develop the first-of-its-kind framework dubbed O-HAS, which for the first time demonstrates automated Optical Hardware Accelerator Search for boosting both the acceleration efficiency and development speed of optical DNN accelerators. Specifically, our O-HAS consists of two integrated enablers: (1) an O-Cost Predictor, which can accurately yet efficiently predict an optical accelerator's energy and latency based on the DNN model parameters and the optical accelerator design; and (2) an O-Search Engine, which can automatically explore the large design space of optical DNN accelerators and identify the optimal accelerators (i.e., the micro-architectures and algorithm-to-accelerator mapping methods) in order to maximize the target acceleration efficiency. Extensive experiments and ablation studies consistently validate the effectiveness of both our O-Cost Predictor and O-Search Engine as well as the excellent efficiency of O-HAS generated optical accelerators. All codes, performance models, and searched optical accelerators will be released upon acceptance.
Graph Neural Networks (GNNs) have emerged as the state-of-the-art (SOTA) method for graph-based learning tasks. However, it still remains prohibitively challenging to inference GNNs over large graph datasets, limiting their application to large-scale real-world tasks. While end-to-end jointly optimizing GNNs and their accelerators is promising in boosting GNNs’ inference efficiency and expediting the design process, it is still underexplored due to the vast and distinct design spaces of GNNs and their accelerators. In this work, we propose G-CoS, a GNN and accelerator co-search framework that can automatically search for matched GNN structures and accelerators to maximize both task accuracy and acceleration efficiency. Specifically, G-CoS integrates two major enabling components: (1) a generic GNN accelerator search space which is applicable to various GNN structures and (2) a one-shot GNN and accelerator co-search algorithm that enables simultaneous and efficient search for optimal GNN structures and their matched accelerators. To the best of our knowledge, G-CoS is the first co-search framework for GNNs and their accelerators. Extensive experiments and ablation studies show that the GNNs and accelerators generated by G-CoS consistently outperform SOTA GNNs and GNN accelerators in terms of both task accuracy and hardware efficiency, while only requiring a few hours for the end-to-end generation of the best matched GNNs and their accelerators.
There has been a booming demand for integrating Convolutional Neural Networks (CNNs) powered functionalities into Internet-of-Thing (IoT) devices to enable ubiquitous intelligent ``IoT cameras”. However, more extensive applications of such IoT systems are still limited by two challenges. First, some applications, especially medicine- and wearable-related ones, impose stringent requirements on the camera form factor. Second, powerful CNNs often require considerable storage and energy cost, whereas IoT devices often suffer from limited resources. PhlatCam, with its form factor potentially reduced by orders of magnitude, has emerged as a promising solution to the first aforementioned challenge, while the second one remains a bottleneck. Existing compression techniques, which can potentially tackle the second challenge, are far from realizing the full potential in storage and energy reduction, because they mostly focus on the CNN algorithm itself. To this end, this work proposes SACoD, a Sensor Algorithm Co-Design framework to develop more efficient CNN-powered PhlatCam. In particular, the mask coded in the PhlatCam sensor and the backend CNN model are jointly optimized in terms of both model parameters and architectures via differential neural architecture search. Extensive experiments including both simulation and physical measurement on manufactured masks show that the proposed SACoD framework achieves aggressive model compression and energy savings while maintaining or even boosting the task accuracy, when benchmarking over two state-of-the-art (SOTA) designs with six datasets across four different vision tasks including classification, segmentation, image translation, and face recognition.
The recent breakthroughs of deep neural networks (DNNs) and the advent of billions of Internet of Things (IoT) devices have excited an explosive demand for intelligent IoT devices equipped with domain-specific DNN accelerators. However, the deployment of DNN accelerator enabled intelligent functionality into real-world IoT devices still remains particularly challenging. First, powerful DNNs often come at a prohibitive complexity, whereas IoT devices often suffer from stringent resource constraints. Second, while DNNs are vulnerable to adversarial attacks especially on IoT devices exposed to complex real-world environments, many IoT applications require strict security. Existing DNN accelerators mostly tackle only one of the two aforementioned challenges (i.e., efficiency or adversarial robustness) while neglecting or even sacrificing the other. To this end, we propose a 2-in-1 Accelerator, an integrated algorithm-accelerator co-design framework aiming at winning both the adversarial robustness and efficiency of DNN accelerators. Specifically, we first propose a Random Precision Switch (RPS) algorithm that can effectively defend DNNs against adversarial attacks by enabling random DNN quantization as an in-situ model switch during training and inference. Furthermore, we propose a new precision-scalable accelerator featuring (1) a new precision-scalable MAC unit architecture which spatially tiles the temporal MAC units to boost both the achievable efficiency and flexibility and (2) a systematically optimized dataflow that is searched by our generic accelerator optimizer. Extensive experiments and ablation studies validate that our 2-in-1 Accelerator can not only aggressively boost both the adversarial robustness and efficiency of DNN accelerators under various attacks, but also naturally support instantaneous robustness-efficiency trade-offs adapting to varied resources without the necessity of DNN retraining. We believe our 2-in-1 Accelerator has opened up an exciting perspective of robust and efficient accelerator design.
Graph Convolutional Networks (GCNs) have drawn tremendous attention in the past three years due to their unique ability to accurately extract and analyze latent information from graph data structures. Compared with other conventional deep learning modalities, high-performance hardware acceleration of GCNs is similarly critical, but even more challenging. The hurdles mainly arise from the poor data locality and redundant computation due to the large size, high sparsity, and irregular non-zero distribution of real-world graphs.
In this paper, we propose a novel hardware accelerator for GCN inference called I-GCN that significantly improves data locality and reduces unnecessary computation through a new online graph restructuring algorithm we refer to as islandization. The proposed algorithm finds clusters of nodes with strong internal but weak external connections. The islandization process yields two major benefits. First, by processing islands rather than individual nodes, there is better on-chip data reuse and fewer off-chip memory accesses. Second, there is less redundant computation as aggregation for common/shared neighbors in an island can be reused. The parallel search, identification, and leverage of graph islands are all handled purely in hardware at runtime working in an incremental pipelined manner. This is done without any preprocessing of the graph data or adjustment of the GCN model structure. Experimental results show that I-GCN can significantly reduce off-chip accesses and prune 37% of aggregation operations, leading to performance speedups over CPUs, GPUs, the prior-art GCN accelerators of 7486x, 185x, and 3.7x, respectively.
We present DIAN, a Differentiable Accelerator Network Co-Search framework for automatically searching for matched networks and accelerators to maximize both the accuracy and efficiency. Specifically, DIAN integrates two enablers: (1) a generic design space for DNN accelerators that is applicable to both FPGA- and ASIC-based DNN accelerators; and (2) a joint DNN network and accelerator co-search algorithm that enables the simultaneous search for optimal DNN structures and their accelerators. Experiments and ablation studies based on FPGA measurements and ASIC synthesis show that the matched networks and accelerators generated by DIAN consistently outperform state-of-the-art (SOTA) DNNs and DNN accelerators (e.g., 3.04× better FPS with a 5.46% higher accuracy on ImageNet), while requiring notably reduced search time (up to 1234.3×) over SOTA co-exploration methods, when evaluated over ten SOTA baselines on three datasets
While maximizing deep neural networks' (DNNs') acceleration efficiency requires a joint search/design of three different yet highly coupled aspects, including the networks, bitwidths, and accelerators, the challenges associated with such a joint search have not yet been fully understood and addressed. The key challenges include (1) the dilemma of whether to explode the memory consumption due to the huge joint space or achieve sub-optimal designs, (2) the discrete nature of the accelerator design space that is coupled yet different from that of the networks and bitwidths, and (3) the chicken and egg problem associated with network-accelerator co-search, i.e., co-search requires operation-wise hardware cost, which is lacking during search as the optimal accelerator depending on the whole network is still unknown during search. To tackle these daunting challenges towards optimal and fast development of DNN accelerators, we propose a framework dubbed Auto-NBA to enable jointly searching for the Networks, Bitwidths, and Accelerators, by efficiently localizing the optimal design within the huge joint design space for each target dataset and acceleration specification. Our Auto-NBA integrates a heterogeneous sampling strategy to achieve unbiased search with constant memory consumption, and a novel joint-search pipeline equipped with a generic differentiable accelerator search engine. Extensive experiments and ablation studies validate that both Auto-NBA generated networks and accelerators consistently outperform state-of-the-art designs (including co-search/exploration techniques, hardware-aware NAS methods, and DNN accelerators), in terms of search time, task accuracy, and accelerator efficiency.

Quantization is promising in enabling powerful yet complex deep neural networks (DNNs) to be deployed into resource constrained platforms. However, quantized DNNs are vulnerable to adversarial attacks unless being equipped with sophisticated techniques, leading to a dilemma of struggling between DNNs' efficiency and robustness, both of which are critical for many DNN applications. In this work, we demonstrate a new perspective regarding quantization's role in DNNs' robustness, advocating that quantization can be leveraged to largely boost DNNs’ robustness, and propose a framework dubbed Double-Win Quant that can boost the robustness of quantized DNNs over their full precision counterparts by a large margin. Specifically, we for the first time identify that when an adversarially trained model is quantized to different precisions in a post-training manner, the associated adversarial attacks transfer poorly between different precisions; Leveraging this intriguing observation, we further develop Double-Win Quant integrating random precision inference and training to enable an aggressive "win-win" in terms of DNNs' robustness and efficiency. Extensive experiments and ablation studies consistently validate Double-Win Quant's effectiveness and advantages over state-of-the-art adversarial training methods across various attacks/models/datasets.
The promise of Deep Neural Network (DNN) powered Internet of Thing (IoT) devices has motivated a tremendous demand for automated solutions to enable fast development and deployment of efficient (1) DNNs equipped with instantaneous accuracy-efficiency trade-off capability to accommodate the time-varying resources at IoT devices and (2) dataflows to optimize the execution efficiency of DNNs on different devices. Therefore, we propose InstantNet to automatically generate and deploy instantaneously switchable-precision networks which can operate at variable bit-widths. Extensive experiments show that the proposed InstantNet consistently outperforms state-of-the-art designs.
Driven by the explosive interest in applying deep reinforcement learning (DRL) agents for numerous real-time control and decision-making applications, there has been a growing demand to deploy DRL agents to empower daily-life intelligent devices, while the prohibitive complexity of DRL stands at the odds with the limited on-device resources. In this work, we propose an Automated Agent Accelerator Co-Search (A3C-S) framework, which to our best knowledge is the first to automatically co-search the optimally matched DRL agents and accelerators that maximize both the test scores and hardware efficiency. Extensive experiments consistently validate the superiority of our A3C-S over state-of-the-art techniques.
Low-precision deep neural network (DNN) training has gained tremendous attention as reducing precision is one of the most effective knobs for boosting DNNs' training time/energy efficiency. In this paper, we attempt to explore low-precision training from a new perspective as inspired by recent findings in understanding DNN training: we conjecture that DNNs' precision might have a similar effect as the learning rate during DNN training, and advocate dynamic precision along the training trajectory for further boosting the time/energy efficiency of DNN training. Specifically, we propose Cyclic Precision Training (CPT) to cyclically vary the precision between two boundary values which can be identified using a simple precision range test within the first few training epochs. Extensive simulations and ablation studies on five datasets and ten models demonstrate that CPT's effectiveness is consistent across various models/tasks (including classification and language modeling). Furthermore, through experiments and visualization we show that CPT helps to (1) converge to a wider minima with a lower generalization error and (2) reduce training variance which we believe opens up a new design knob for simultaneously improving the optimization and efficiency of DNN training.
HardWare-aware Neural Architecture Search (HW-NAS) has recently gained tremendous attention for automating the design of DNNs to be deployed into more resource-constrained daily life devices. Despite their promising performance, developing optimal HW-NAS solutions can be prohibitively challenging as it requires cross-disciplinary knowledge in the algorithm, micro-architecture, and device-specific compilation. First, to construct the hardware cost to be incorporated into the NAS process, existing works mostly adopt either pre-collected cost look-up tables or device-specific hardware cost models. The former can be time-consuming due to the needed learning about the device's compilation method and how to set up the measurement pipeline, while the latter is often a barrier for non-hardware experts like NAS researchers. Both of them limit the development of HW-NAS innovations and impose a barrier-to-entry to non-hardware experts. Second, similar to generic NAS, it can be notoriously difficult to benchmark HW-NAS algorithms due to the required significant computational resources and the differences in their adopted search space, hyperparameters, and hardware devices. To this end, we develop HW-NAS-Bench, the first public dataset for HW-NAS research which aims to democratize HW-NAS research to non-hardware experts and make HW-NAS research more reproducible and accessible. To design HW-NAS-Bench, we carefully collected the measured/estimated hardware performance (e.g., energy cost and latency) of all the networks in the search space of both NAS-Bench-201 and FBNet, considering six hardware devices that fall into three categories (i.e., commercial edge devices, FPGA, and ASIC). Furthermore, we provide a comprehensive analysis of the collected measurements in HW-NAS-Bench to provide insights for HW-NAS research. Finally, we demonstrate exemplary user cases when HW-NAS-Bench (1) allows non-hardware experts to perform HW-NAS by simply querying our pre-measured dataset and (2) verify that dedicated device-specific HW-NAS can indeed often provide optimal accuracy-cost trade-offs. All the codes and data will be released publicly upon acceptance.
[JETC 2021]
Neural Network and Accelerator Search Towards Effective and Real-time ECG Reconstruction from Intracardiac Electrograms
Yongan Zhang, Anton Banta, Yonggan Fu, Mathews M. John, Allison Post, Mehdi Razavi, Joseph R. Cavallaro, Behnaam Aazhang, and Yingyan (Celine) Lin
[Abstract] [Paper] [Slides]
Yongan Zhang, Anton Banta, Yonggan Fu, Mathews M. John, Allison Post, Mehdi Razavi, Joseph R. Cavallaro, Behnaam Aazhang, and Yingyan (Celine) Lin
[Abstract] [Paper] [Slides]
There exists a gap in terms of the signals provided by pacemakers (i.e., intracardiac electrogram (EGM)) and the signals doctors use (i.e., 12-lead electrocardiogram (ECG)) to diagnose abnormal rhythms. Therefore, the former, even if remotely transmitted, are not sufficient for the doctors to provide precise diagnosis, let alone timely intervention. To close this gap and make a heuristic step towards real-time critical intervention in instant response to irregular and infrequent ventricular rhythms, we propose a new framework dubbed RT-RCG to automatically search for (1) efficient Deep Neural Network (DNN) structures and then (2) corresponding accelerators, to enable Real-Time and high-quality Reconstruction of ECG signals from EGM signals. Specifically, RT-RCG proposes a new DNN search space tailored for ECG reconstruction from EGM signals, and incorporates a differentiable acceleration search (DAS) engine to efficiently navigate over the large and discrete accelerator design space to generate optimized accelerators. Extensive experiments and ablation studies under various settings consistently validate the effectiveness of our RT-RCG. To the best of our knowledge, RT-RCG is the first to leverage neural architecture search (NAS) to simultaneously tackle both the reconstruction efficacy and efficiency.
Multiplication (e.g., convolution) is arguably a cornerstone of modern deep neural networks (DNNs). However, intensive multiplications cause expensive resource costs that challenge DNNs' deployment on resource-constrained edge devices, driving several attempts for multiplication-less deep networks. This paper presented ShiftAddNet, whose main inspiration is drawn from a common practice in energy-efficient hardware implementation, that is, multiplication can be instead performed with additions and logical bit-shifts. We leverage this idea to explicitly parameterize deep networks in this way, yielding a new type of deep network that involves only bit-shift and additive weight layers. This hardware-inspired ShiftAddNet immediately leads to both energy-efficient inference and training, without compromising the expressive capacity compared to standard DNNs. The two complementary operation types (bit-shift and add) additionally enable finer-grained control of the model's learning capacity, leading to more flexible trade-off between accuracy and (training) efficiency, as well as improved robustness to quantization and pruning. We conduct extensive experiments and ablation studies, all backed up by our FPGA-based ShiftAddNet implementation and energy measurements. Compared to existing DNNs or other multiplication-less models, ShiftAddNet aggressively reduces over 80% hardware-quantified energy cost of DNNs training and inference, while offering comparable or better accuracies. Codes and pre-trained models are available at https://github.com/RICE-EIC/ShiftAddNet.
Recent breakthroughs in deep neural networks (DNNs) have fueled a tremendous demand for intelligent edge devices featuring on-site learning, while the practical realization of such systems remains a challenge due to the limited resources available at the edge and the required massive training costs for state-of-the-art (SOTA) DNNs. As reducing precision is one of the most effective knobs for boosting training time/energy efficiency, there has been a growing interest in low-precision DNN training. In this paper, we explore from an orthogonal direction: how to fractionally squeeze out more training cost savings from the most redundant bit level, progressively along the training trajectory and dynamically per input. Specifically, we propose FracTrain that integrates (i) progressive fractional quantization which gradually increases the precision of activations, weights, and gradients that will not reach the precision of SOTA static quantized DNN training until the final training stage, and (ii) dynamic fractional quantization which assigns precisions to both the activations and gradients of each layer in an input-adaptive manner, for only "fractionally" updating layer parameters. Extensive simulations and ablation studies (six models, four datasets, and three training settings including standard, adaptation, and fine-tuning) validate the effectiveness of FracTrain in reducing computational cost and hardware-quantified energy/latency of DNN training while achieving a comparable or better (-0.12%~+1.87%) accuracy. For example, when training ResNet-74 on CIFAR-10, FracTrain achieves 77.6% and 53.5% computational cost and training latency savings, respectively, compared with the best SOTA baseline, while achieving a comparable (-0.07%) accuracy. Our codes are available at: https://github.com/RICE-EIC/FracTrain.
There has been an explosive demand for bringing machine learning (ML) powered intelligence into numerous Internet-of-Things (IoT) devices. However, the effectiveness of such intelligent functionality requires in-situ continuous model adaptation for adapting to new data and environments, while the on-device computing and energy resources are usually extremely constrained. Neither traditional hand-crafted (e.g., SGD, Adagrad, and Adam) nor existing meta optimizers are specifically designed to meet those challenges, as the former requires tedious hyper-parameter tuning while the latter are often costly due to the meta algorithms' own overhead. To this end, we propose hardware-aware learning to optimize (HALO), a practical meta optimizer dedicated to resource-efficient on-device adaptation. Our HALO optimizer features the following highlights: (1) faster adaptation speed (i.e., taking fewer data or iterations to reach a specified accuracy) by introducing a new regularizer to promote empirical generalization; and (2) lower per-iteration complexity, thanks to a stochastic structural sparsity regularizer being enforced. Furthermore, the optimizer itself is designed as a very light-weight RNN and thus incurs negligible overhead. Ablation studies and experiments on five datasets, six optimizees, and two state-of-the-art (SOTA) edge AI devices validate that, while always achieving a better accuracy ({$}{$}{backslash}uparrow {$}{$}{textuparrow}0.46{%} - {$}{$}{backslash}uparrow {$}{$}{textuparrow}20.28{%}), HALO can greatly trim down the energy cost (up to {$}{$}{backslash}downarrow {$}{$}{textdownarrow}60{%}) in adaptation, quantified using an IoT device or SOTA simulator. Codes and pre-trained models are at https://github.com/RICE-EIC/HALO.
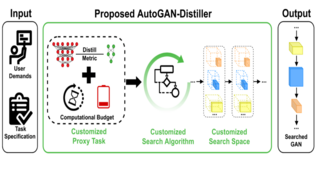
The compression of Generative Adversarial Networks (GANs) has lately drawn attention, due to the increasing demand for deploying GANs into mobile devices for numerous applications such as image translation, enhancement and editing. However, compared to the substantial efforts to compressing other deep models, the research on compressing GANs (usually the generators) remains at its infancy stage. Existing GAN compression algorithms are limited to handling specific GAN architectures and losses. Inspired by the recent success of AutoML in deep compression, we introduce AutoML to GAN compression and develop an AutoGAN-Distiller (AGD) framework. Starting with a specifically designed efficient search space, AGD performs an end-to-end discovery for new efficient generators, given the target computational resource constraints. The search is guided by the original GAN model via knowledge distillation, therefore fulfilling the compression. AGD is fully automatic, standalone (i.e., needing no trained discriminators), and generically applicable to various GAN models. We evaluate AGD in two representative GAN tasks: image translation and super resolution. Without bells and whistles, AGD yields remarkably lightweight yet more competitive compressed models, that largely outperform existing alternatives. Our codes and pretrained models are available at: https://github.com/TAMU-VITA/AGD.
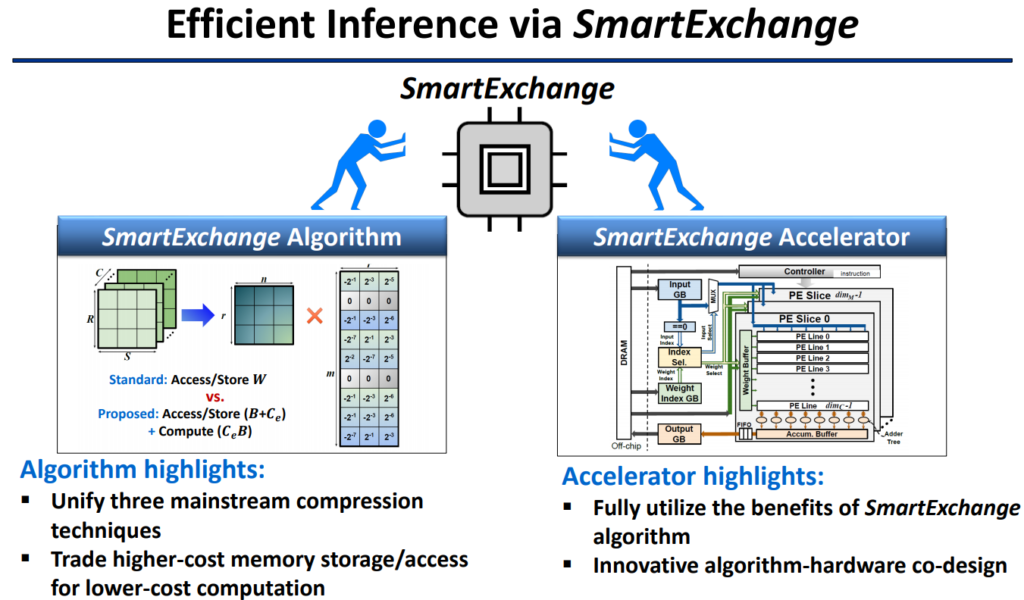
We present SmartExchange, an algorithm-hardware co-design framework to trade higher-cost memory storage/access for lower-cost computation, for energy-efficient inference of deep neural networks (DNNs). We develop a novel algorithm to enforce a specially favorable DNN weight structure, where each layerwise weight matrix can be stored as the product of a small basis matrix and a large sparse coefficient matrix whose non-zero elements are all power-of-2. To our best knowledge, this algorithm is the first formulation that integrates three mainstream model compression ideas: sparsification or pruning, decomposition, and quantization, into one unified framework. The resulting sparse and readily-quantized DNN thus enjoys greatly reduced energy consumption in data movement as well as weight storage. On top of that, we further design a dedicated accelerator to fully utilize the SmartExchange-enforced weights to improve both energy efficiency and latency performance. Extensive experiments show that 1) on the algorithm level, SmartExchange outperforms stateof-the-art compression techniques, including merely sparsification or pruning, decomposition, and quantization, in various ablation studies based on nine models and four datasets; and 2) on the hardware level, SmartExchange can boost the energy efficiency by up to 6.7× and reduce the latency by up to 19.2× over four state-of-the-art DNN accelerators, when benchmarked on seven DNN models (including four standard DNNs, two compact DNN models, and one segmentation model) and three datasets.
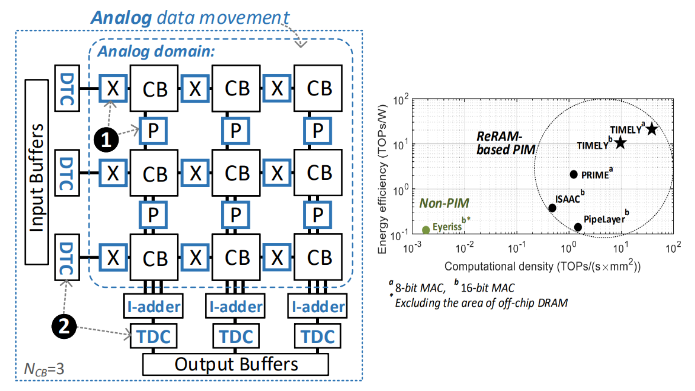
Resistive-random-access-memory (ReRAM) based processing-in-memory (R2PIM) accelerators show promise in bridging the gap between Internet of Thing devices' constrained resources and Convolutional/Deep Neural Networks' (CNNs/DNNs') prohibitive energy cost. Specifically, R2PIM accelerators enhance energy efficiency by eliminating the cost of weight movements and improving the computational density through ReRAM's high density. However, the energy efficiency is still limited by the dominant energy cost of input and partial sum (Psum) movements and the cost of digital-to-analog (D/A) and analog-to-digital (A/D) interfaces. In this work, we identify three energy-saving opportunities in R2PIM accelerators: analog data locality, time-domain interfacing, and input access reduction, and propose an innovative R2PIM accelerator called TIMELY, with three key contributions: (1) TIMELY adopts analog local buffers (ALBs) within ReRAM crossbars to greatly enhance the data locality, minimizing the energy overheads of both input and Psum movements; (2) TIMELY largely reduces the energy of each single D/A (and A/D) conversion and the total number of conversions by using time-domain interfaces (TDIs) and the employed ALBs, respectively; (3) we develop an only-once input read (O2IR) mapping method to further decrease the energy of input accesses and the number of D/A conversions. The evaluation with more than 10 CNN/DNN models and various chip configurations shows that, TIMELY outperforms the baseline R2PIM accelerator, PRIME, by one order of magnitude in energy efficiency while maintaining better computational density (up to 31.2×) and throughput (up to 736.6×). Furthermore, comprehensive studies are performed to evaluate the effectiveness of the proposed ALB, TDI, and O2IR in terms of energy savings and area reduction.
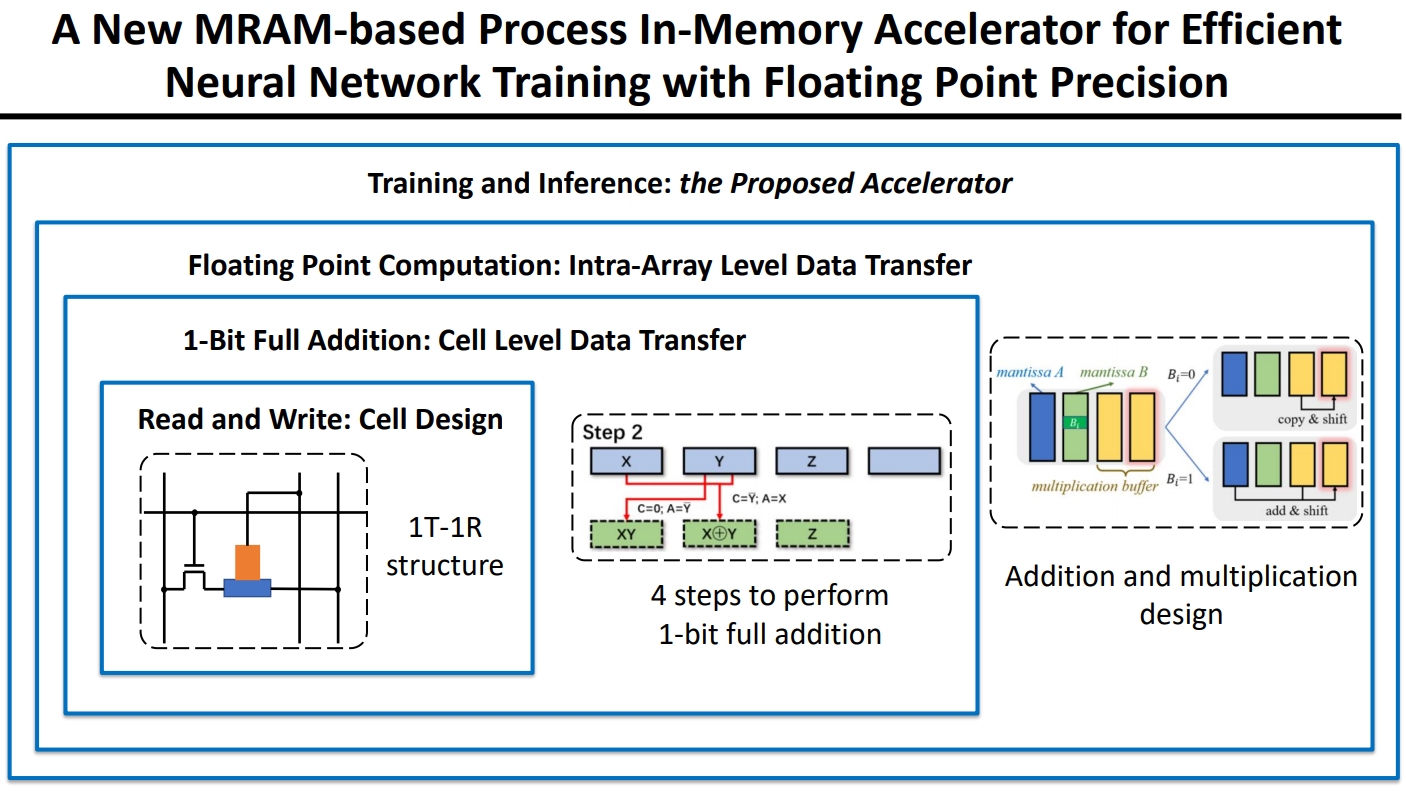
The excellent performance of modern deep neural networks (DNNs) comes at an often prohibitive training cost, limiting the rapid development of DNN innovations and raising various environmental concerns. To reduce the dominant data movement cost of training, process in-memory (PIM) has emerged as a promising solution as it alleviates the need to access DNN weights. However, state-of-the-art PIM DNN training accelerators employ either analog/mixed signal computing which has limited precision or digital computing based on a memory technology that supports limited logic functions and thus requires complicated procedure to realize floating point computation. In this paper, we propose a spin orbit torque magnetic random access memory (SOT-MRAM) based digital PIM accelerator that supports floating point precision. Specifically, this new accelerator features an innovative (1) SOT-MRAM cell, (2) full addition design, and (3) floating point computation. Experiment results show that the proposed SOT-MRAM PIM based DNN training accelerator can achieve 3.3×, 1.8×, and 2.5× improvement in terms of energy, latency, and area, respectively, compared with a state-of-the-art PIM based DNN training accelerator.
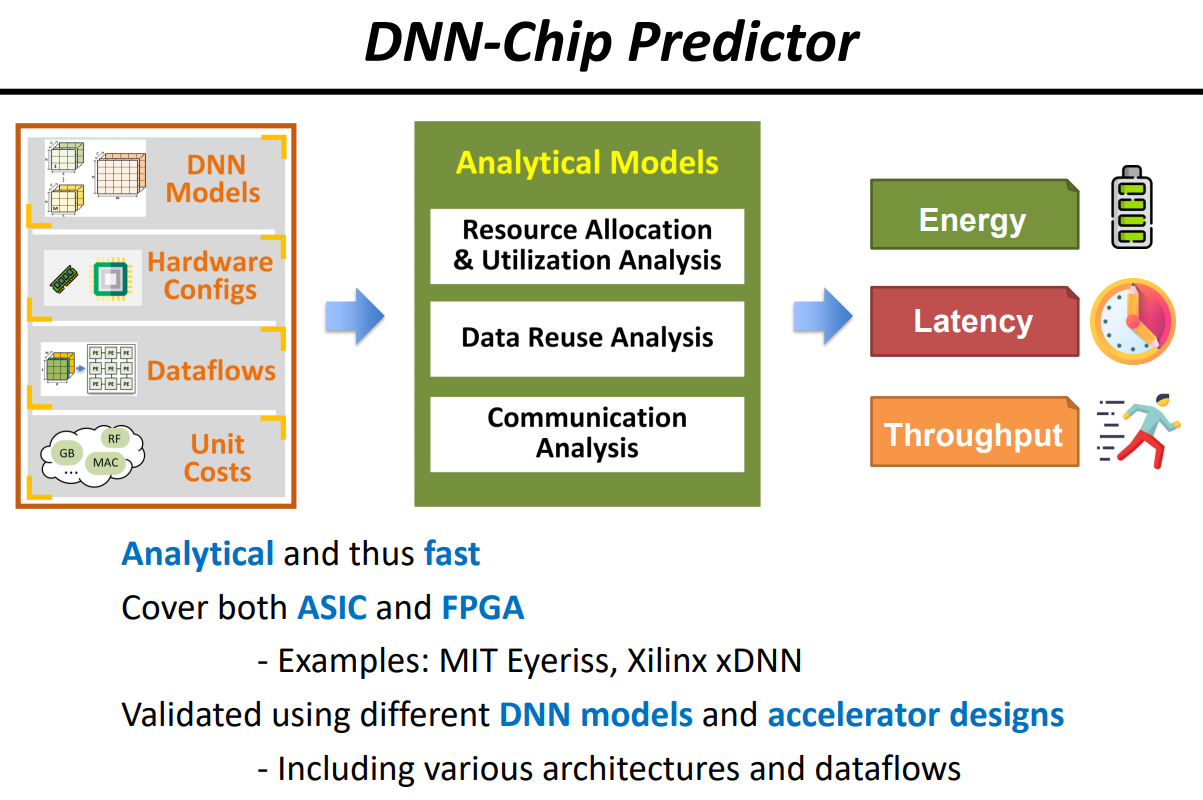
The recent breakthroughs in deep neural networks (DNNs) have spurred a tremendously increased demand for DNN accelerators. However, designing DNN accelerators is non-trivial as it often takes months/years and requires cross-disciplinary knowledge. To enable fast and effective DNN accelerator development, we propose DNN-Chip Predictor, an analytical performance predictor which can accurately predict DNN accelerators' energy, throughput, and latency prior to their actual implementation. Our Predictor features two highlights: (1) its analytical performance formulation of DNN ASIC/FPGA accelerators facilitates fast design space exploration and optimization; and (2) it supports DNN accelerators with different algorithm-to-hardware mapping methods (i.e., dataflows) and hardware architectures. Experiment results based on 2 DNN models and 3 different ASIC/FPGA implementations show that our DNN-Chip Predictor's predicted performance differs from those of chip measurements of FPGA/ASIC implementation by no more than 17.66% when using different DNN models, hardware architectures, and dataflows. We will release code upon acceptance.
[ICLR 2020]
Drawing Early-Bird Tickets: Toward More Efficient Training of Deep Networks
Haoran You, Chaojian Li, Pengfei Xu, Yonggan Fu, Yue Wang, Xiaohan Chen, Richard G Baraniuk, Zhangyang Wang, and Yingyan (Celine) Lin
Spotlight paper, acceptance rate: 4%
[Abstract] [Paper] [Code] [Video] [Slides]
Haoran You, Chaojian Li, Pengfei Xu, Yonggan Fu, Yue Wang, Xiaohan Chen, Richard G Baraniuk, Zhangyang Wang, and Yingyan (Celine) Lin
Spotlight paper, acceptance rate: 4%
[Abstract] [Paper] [Code] [Video] [Slides]
(Frankle & Carbin, 2019) shows that there exist winning tickets (small but critical subnetworks) for dense, randomly initialized networks, that can be trained alone to achieve comparable accuracies to the latter in a similar number of iterations. However, the identification of these winning tickets still requires the costly train-prune-retrain process, limiting their practical benefits. In this paper, we discover for the first time that the winning tickets can be identified at the very early training stage, which we term as Early-Bird (EB) tickets, via low-cost training schemes (e.g., early stopping and low-precision training) at large learning rates. Our finding of EB tickets is consistent with recently reported observations that the key connectivity patterns of neural networks emerge early. Furthermore, we propose a mask distance metric that can be used to identify EB tickets with low computational overhead, without needing to know the true winning tickets that emerge after the full training. Finally, we leverage the existence of EB tickets and the proposed mask distance to develop efficient training methods, which are achieved by first identifying EB tickets via low-cost schemes, and then continuing to train merely the EB tickets towards the target accuracy. Experiments based on various deep networks and datasets validate: 1) the existence of EB tickets, and the effectiveness of mask distance in efficiently identifying them; and 2) that the proposed efficient training via EB tickets can achieve up to 4.7x energy savings while maintaining comparable or even better accuracy, demonstrating a promising and easily adopted method for tackling cost-prohibitive deep network training. Code available at https://github.com/RICE-EIC/Early-Bird-Tickets.
While increasingly deep networks are still in general desired for achieving state-of-the-art performance, for many specific inputs a simpler network might already suffice. Existing works exploited this observation by learning to skip convolutional layers in an input-dependent manner. However, we argue their binary decision scheme, i.e., either fully executing or completely bypassing one layer for a specific input, can be enhanced by introducing finer-grained, “softer” decisions. We therefore propose a Dynamic Fractional Skipping (DFS) framework. The core idea of DFS is to hypothesize layer-wise quantization (to different bitwidths) as intermediate “soft” choices to be made between fully utilizing and skipping a layer. For each input, DFS dynamically assigns a bitwidth to both weights and activations of each layer, where fully executing and skipping could be viewed as two “extremes” (i.e., full bitwidth and zero bitwidth). In this way, DFS can “fractionally” exploit a layer's expressive power during input-adaptive inference, enabling finer-grained accuracy-computational cost trade-offs. It presents a unified view to link input-adaptive layer skipping and input-adaptive hybrid quantization. Extensive experimental results demonstrate the superior tradeoff between computational cost and model expressive power (accuracy) achieved by DFS. More visualizations also indicate a smooth and consistent transition in the DFS behaviors, especially the learned choices between layer skipping and different quantizations when the total computational budgets vary, validating our hypothesis that layer quantization could be viewed as intermediate variants of layer skipping. Our source code and supplementary material are available at https://github.com/Torment123/DFS.
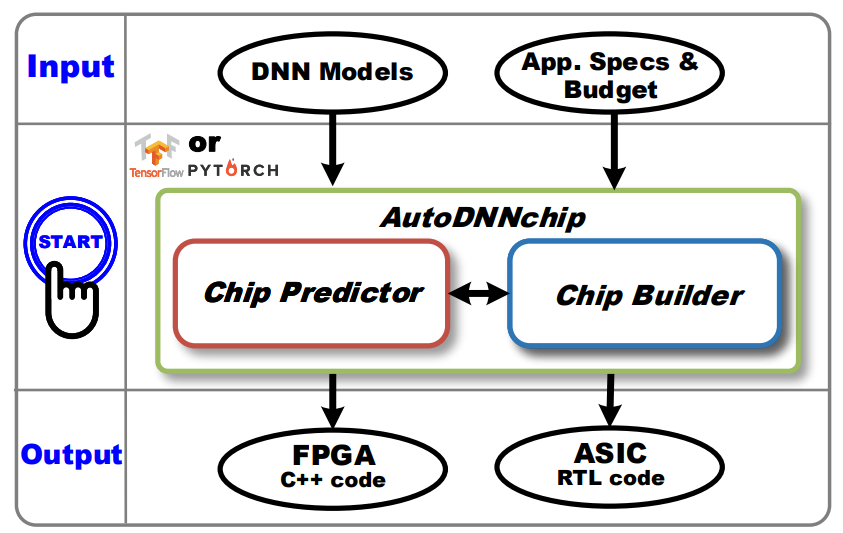
Recent breakthroughs in Deep Neural Networks (DNNs) have fueled a growing demand for domain-specific hardware accelerators (i.e., DNN chips). However, designing DNN chips is non-trivial because: (1) mainstream DNNs have millions of parameters and billions of operations; (2) the design space is large due to numerous design choices of dataflows, processing elements, memory hierarchy, etc.; and (3) there is an algorithm/hardware co-design need for the same DNN functionality to have a different decomposition that would require different hardware IPs and thus correspond to dramatically different performance/energy/area tradeoffs. Therefore, DNN chips often take months to years to design and require a large team of cross-disciplinary experts. To enable fast and effective DNN chip design, we propose AutoDNNchip - a DNN chip generator that can automatically produce both FPGA- and ASIC-based DNN chip implementation (i.e., synthesizable RTL code with optimized algorithm-to-hardware mapping) from DNNs developed by machine learning frameworks (e.g., PyTorch) for a designated application and dataset without humans in the loop. Specifically, AutoDNNchip consists of 2 integrated enablers: (1) a Chip Predictor, which can accurately and efficiently predict a DNN accelerator's energy, throughput, latency, and area based on the DNN model parameters, hardware configurations, technology-based IPs, and platform constraints; and (2) a Chip Builder, which can automatically explore the design space of DNN chips (including IP selections, block configurations, resource balancing, etc.), optimize chip designs via the Chip Predictor, and then generate synthesizable RTL code with optimized dataflows to achieve the target design metrics. Experimental results show that our Chip Predictor's predicted performance differs from real-measured ones by over 10% when validated using 15 DNN models and 4 platforms (edge-FPGA/TPU/GPU and ASIC). Furthermore, DNN accelerators generated by our AutoDNNchip can achieve better (up to 3.86X improvement) performance than that of expert-crafted state-of-the-art FPGA- and ASIC-based accelerators, showing the effectiveness of AutoDNNchip. Our open-source code can be found at https://github.com/RICE-EIC/AutoDNNchip.git.
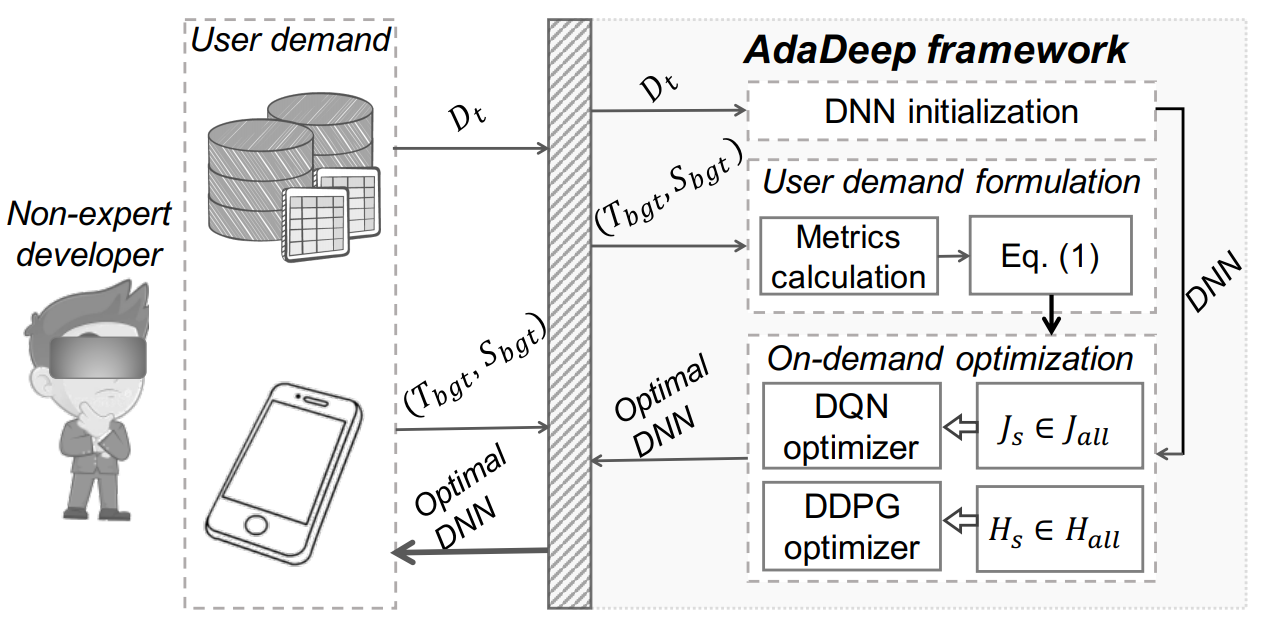
Recent breakthroughs in Deep Neural Networks (DNNs) have fueled a tremendously growing demand for bringing DNN-powered intelligence into mobile platforms. While the potential of deploying DNNs on resource-constrained platforms has been demonstrated by DNN compression techniques, the current practice suffers from two limitations: 1) merely stand-alone compression schemes are investigated even though each compression technique only suit for certain types of DNN layers; and 2) mostly compression techniques are optimized for DNNs' inference accuracy, without explicitly considering other application-driven system performance (e.g., latency and energy cost) and the varying resource availability across platforms (e.g., storage and processing capability). To this end, we propose AdaDeep, a usage-driven, automated DNN compression framework for systematically exploring the desired trade-off between performance and resource constraints, from a holistic system level. Specifically, in a layer-wise manner, AdaDeep automatically selects the most suitable combination of compression techniques and the corresponding compression hyperparameters for a given DNN. Thorough evaluations on six datasets and across twelve devices demonstrate that AdaDeep can achieve up to 18.6x latency reduction, 9.8x energy-efficiency improvement, and 37.3x storage reduction in DNNs while incurring negligible accuracy loss. Furthermore, AdaDeep also uncovers multiple novel combinations of compression techniques.
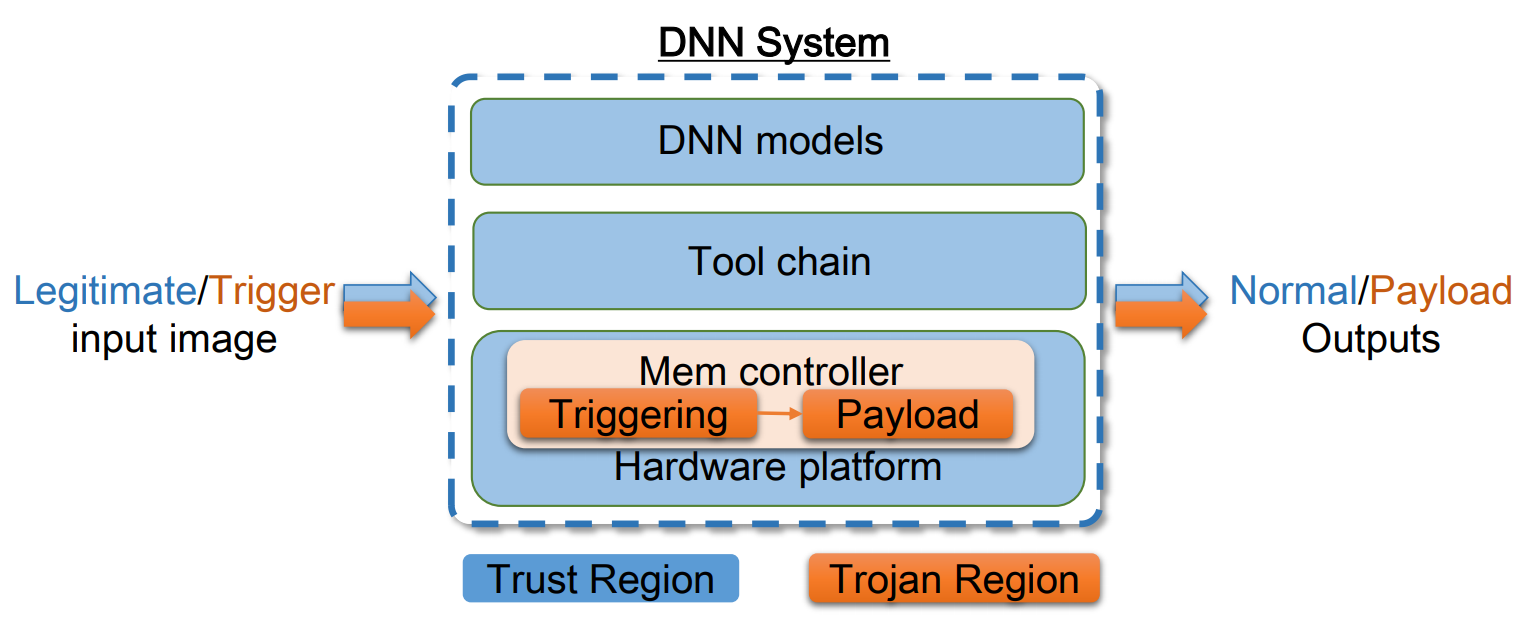
Deep Neural Network (DNN) accelerators are widely deployed in computer vision, speech recognition, and machine translation applications, in which attacks on DNNs have become a growing concern. This work focuses on exploring the implications of hardware Trojan attacks on DNNs. Trojans are one of the most challenging threat models in hardware security where adversaries insert malicious modifications to the original integrated circuits (ICs), leading to malfunction once being triggered. Such attacks can be conducted by adversaries because modern ICs commonly include third-party intellectual property (IP) blocks. Previous studies design hardware Trojans to attack DNNs with the assumption that adversaries have full knowledge or manipulation of the DNN systems’ victim model and toolchain in addition to the hardware platforms, yet such a threat model is strict, limiting their practical adoption. In this work, we propose a memory Trojan methodology which implants the malicious logics merely into the memory controllers of DNN systems without the necessity of toolchain manipulation or accessing to the victim model and thus is feasible for practical uses. Specifically, we locate the input image data among the massive volume of memory traffics based on memory access patterns and propose a Trojan trigger mechanism based on detecting geometric feature in input images. Extensive experiments show that the proposed trigger mechanism is effective even in the presence of environmental noises and pre-processing operations. Furthermore, we design and implement the payload and verify that the proposed Trojan technique can effectively conduct both untargeted and targeted attacks on DNNs.
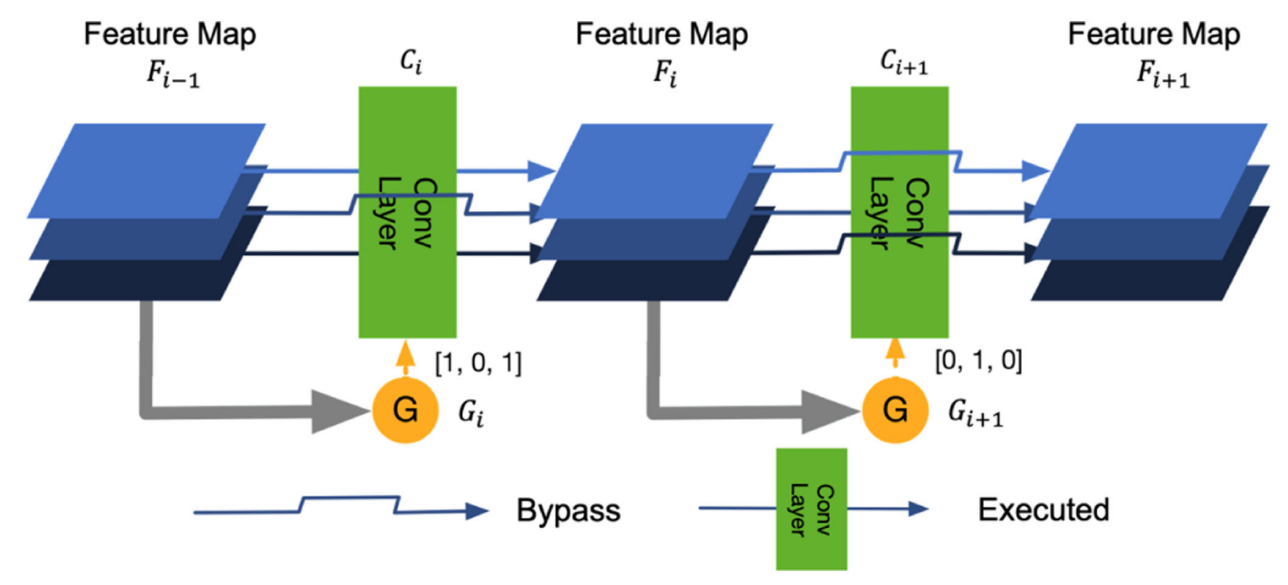
State-of-the-art convolutional neural networks (CNNs) yield record-breaking predictive performance, yet at the cost of high-energy-consumption inference, that prohibits their widely deployments in resource-constrained Internet of Things (IoT) applications. We propose a dual dynamic inference (DDI) framework that highlights the following aspects: 1) we integrate both input-dependent and resource-dependent dynamic inference mechanisms under a unified framework in order to fit the varying IoT resource requirements in practice. DDI is able to both constantly suppress unnecessary costs for easy samples, and to halt inference for all samples to meet hard resource constraints enforced; 2) we propose a flexible multi-grained learning to skip (MGL2S) approach for input-dependent inference which allows simultaneous layer-wise and channel-wise skipping; 3) we extend DDI to complex CNN backbones such as DenseNet and show that DDI can be applied towards optimizing any specific resource goals including inference latency and energy cost. Extensive experiments demonstrate the superior inference accuracy-resource trade-off achieved by DDI, as well as the flexibility to control such a trade-off as compared to existing peer methods. Specifically, DDI can achieve up to 4 times computational savings with the same or even higher accuracy as compared to existing competitive baselines.
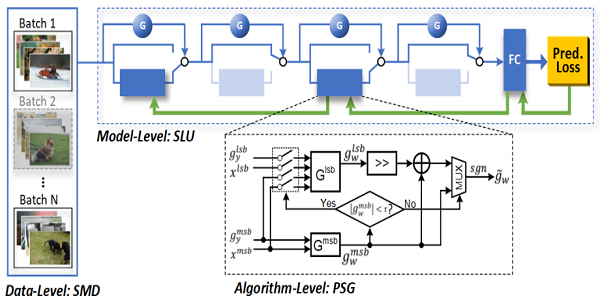
Convolutional neural networks (CNNs) have been increasingly deployed to edge devices. Hence, many efforts have been made towards efficient CNN inference in resource-constrained platforms. This paper attempts to explore an orthogonal direction: how to conduct more energy-efficient training of CNNs, so as to enable on-device training. We strive to reduce the energy cost during training, by dropping unnecessary computations from three complementary levels: stochastic mini-batch dropping on the data level; selective layer update on the model level; and sign prediction for low-cost, low-precision back-propagation, on the algorithm level. Extensive simulations and ablation studies, with real energy measurements from an FPGA board, confirm the superiority of our proposed strategies and demonstrate remarkable energy savings for training. For example, when training ResNet-74 on CIFAR-10, we achieve aggressive energy savings of >90% and >60%, while incurring a top-1 accuracy loss of only about 2% and 1.2%, respectively. When training ResNet-110 on CIFAR-100, an over 84% training energy saving is achieved without degrading inference accuracy.

The record-breaking success of convolutional neural networks (CNNs) comes at the cost of a large amount of model parameters. The resulting prohibitive memory storage and data movement energy have been limiting the extensive deployment of deep learning on daily-life edge devices which usually have limited storage capability and are battery-powered. To this end, we explore the employment of a recently published weight clustering technique, called deep k-Means which makes use of the redundancy within CNN parameters for reduced memory storage and data movement, and demonstrate k-Means's effectiveness in the context of an interactive real-time object detection using three representative daily-life devices (iPhone, iPad and FPGA).
The prohibitive energy cost of running high-performance Convolutional Neural Networks (CNNs) has been limiting their deployment on resource-constrained platforms including mobile and wearable devices. We propose a CNN for energy-aware dynamic routing, called EnergyNet, that achieves adaptive-complexity inference based on the inputs, leading to an overall reduction of run time energy cost while actually improving accuracy. This is achieved by proposing an energy loss that captures both computational and data movement costs. We combine it with the accuracy-oriented loss, and learn a dynamic routing policy for skipping certain layers in the networks that optimizes the hybrid loss. Our empirical results demonstrate that, compared to the baseline CNNs, EnergyNet can trim down the energy cost by up to 40% and 65%, during inference on the CIFAR10 and Tiny ImageNet testing sets, respectively, while maintaining the same testing accuracy. It is further encouraging to observe that the energy awareness might serve as a training regularization that can improve the prediction accuracy: our models can achieve 0.7% higher top-1 testing accuracy than the baseline on CIFAR-10 when saving up to 27% energy, and 1.0% higher top-5 testing accuracy on Tiny ImageNet when saving up to 50% energy, respectively.

The current trend of pushing CNNs deeper with convolutions has created a pressing demand to achieve higher compression gains on CNNs where convolutions dominate the computation and parameter amount (e.g., GoogLeNet, ResNet and Wide ResNet). Further, the high energy consumption of convolutions limits its deployment on mobile devices. To this end, we proposed a simple yet effective scheme for compressing convolutions though applying k-means clustering on the weights, compression is achieved through weight-sharing, by only recording $K$ cluster centers and weight assignment indexes. We then introduced a novel spectrally relaxed $k$-means regularization, which tends to make hard assignments of convolutional layer weights to $K$ learned cluster centers during re-training. We additionally propose an improved set of metrics to estimate energy consumption of CNN hardware implementations, whose estimation results are verified to be consistent with previously proposed energy estimation tool extrapolated from actual hardware measurements. We finally evaluated Deep $k$-Means across several CNN models in terms of both compression ratio and energy consumption reduction, observing promising results without incurring accuracy loss. The code is available at https://github.com/Sandbox3aster/Deep-K-Means
Recent research has demonstrated the potential of deploying deep neural networks (DNNs) on resource-constrained mobile platforms by trimming down the network complexity using different compression techniques. The current practice only investigate stand-alone compression schemes even though each compression technique may be well suited only for certain types of DNN layers. Also, these compression techniques are optimized merely for the inference accuracy of DNNs, without explicitly considering other application-driven system performance (e.g. latency and energy cost) and the varying resource availabilities across platforms (e.g. storage and processing capability). In this paper, we explore the desirable tradeoff between performance and resource constraints by user-specified needs, from a holistic system-level viewpoint. Specifically, we develop a usage-driven selection framework, referred to as AdaDeep, to automatically select a combination of compression techniques for a given DNN, that will lead to an optimal balance between user-specified performance goals and resource constraints. With an extensive evaluation on five public datasets and across twelve mobile devices, experimental results show that AdaDeep enables up to 9.8x latency reduction, 4.3x energy efficiency improvement, and 38x storage reduction in DNNs while incurring negligible accuracy loss. AdaDeep also uncovers multiple effective combinations of compression techniques unexplored in existing literature.
We propose ASTRO, a drone network that realizes three key features: (i) networked drones that coordinate in autonomous flight via software defined radios, (ii) off-grid tetherless flight without requiring a ground control station or air-to-ground network, and (iii) on-board machine learning missions based on on-drone sensor data shared among drones. We implement ASTRO and present a suite of proof-of-concept experiments based on a mission in which a network of ASTRO drones must find and track a mobile spectrum cheater.
There has been a growing need for deploying machine learning algorithms such as convolutional neural networks (CNNs) on resource-constrained edge platforms to enable on-device local inference. Despite CNNs' excellent performance that approaches and sometimes exceeds humans in a large variety of tasks, their often prohibitive complexity remains a major inhibitor. To address the energy challenge, near threshold computing (NTC) has been proposed to aggressively reduce energy consumption, at the cost of increased performance variation due to circuit level statistical behavior. In this paper, we propose a variation-tolerant architecture for CNNs capable of robust operations in the NTC regime for energy efficiency. Specifically, we construct robust CNNs from two low-cost unreliable designs that have different error statistics: a NTC design with full precision, and a K-means approximated design where weight vectors in the CNN are clustered to reduce complexity. When evaluated in CNNs using the MNIST dataset, simulation results in 45 nm CMOS show that the proposed architecture enables robust CNNs operating in the NTC regime. Specifically, the proposed CNN can enhance variation tolerance by 10× and achieve up to 134× reduction in the standard deviation of inference accuracy Pdet while incurring marginal degradation in the median inference accuracy.
There has been a growing interest in implementing complex machine learning algorithms such as convolutional neural networks (CNNs) on lower power embedded platforms to enable on-device learning and inference. Many of these platforms are to be deployed as low power sensor nodes with low to medium throughput requirement. Near threshold voltage (NTV) designs are well-suited for these applications but suffer from a significant increase in variations. In this paper, we propose a variation-tolerant architecture for CNNs capable of operating in NTV regime for energy efficiency. A statistical error compensation (SEC) technique referred to as rank decomposed SEC (RD-SEC) is proposed. The key idea is to exploit inherent redundancy within matrix-vector multiplication (or dot product ensemble), a power-hungry operation in CNNs, to derive low-cost estimators for error detection and compensation. When evaluated in CNNs for both the MNIST and CIFAR-10 datasets, simulation results in 45 nm CMOS show that RD-SEC enables robust CNNs operating in the NTV regime. Specifically, the proposed architecture can achieve up to 11 × improvement in variation tolerance and enable up to 113 × reduction in the standard deviation of detection accuracy Pdet while incurring marginal degradation in the median detection accuracy.
Convolutional neural networks (CNNs) have gained considerable interest due to their record-breaking performance in many recognition tasks. However, the computational complexity of CNNs precludes their deployments on power-constrained embedded platforms. In this paper, we propose predictive CNN (PredictiveNet), which predicts the sparse outputs of the non-linear layers thereby bypassing a majority of computations. PredictiveNet skips a large fraction of convolutions in CNNs at runtime without modifying the CNN structure or requiring additional branch networks. Analysis supported by simulations is provided to justify the proposed technique in terms of its capability to preserve the mean square error (MSE) of the nonlinear layer outputs. When applied to a CNN for handwritten digit recognition, simulation results show that PredictiveNet can reduce the computational cost by a factor of 2.9× compared to a state-of-the-art CNN, while incurring marginal accuracy degradation.
Convolutional neural networks (CNNs) have gained considerable interest due to their state-of-the-art performance in many recognition tasks. However, the computational complexity of CNNs hinders their application on power-constrained embedded platforms. In this paper, we propose a variation-tolerant architecture for CNN capable of operating in near threshold voltage (NTV) regime for energy efficiency. A statistical error compensation (SEC) technique referred to as rank decomposed SEC (RD-SEC) is proposed. RD-SEC is applied to the CNN architecture in NTV in order to correct timing errors that can occur due to process variations. Simulation results in 45nm CMOS show that the proposed architecture can achieve a median detection accuracy Pdet ≥ 0.9 in the presence of gate level delay variation of up to 34%. This represents an 11x improvement in variation tolerance in comparison to a conventional CNN. We further show that RD-SEC-based CNN enables up to 113x reduction in the standard deviation of Pdet compared with the conventional CNN.
[TECHCON 2016]
Statistical Error Compensation for Parallel Signal Processing and Inference Kernels
Yingyan (Celine) Lin, Sai Zhang, and Naresh R. Shanbhag
[Paper]
Yingyan (Celine) Lin, Sai Zhang, and Naresh R. Shanbhag
[Paper]
Analog-to-digital converter (ADC)-based multi-Gb/s serial link receivers have gained increasing attention in the backplane community due to the desire for higher I/O throughput, ease of design portability, and flexibility. However, the power dissipation in such receivers is dominated by the ADC. ADCs in serial links employ signal-to-noise-and-distortion ratio (SNDR) and effective-number-of-bit (ENOB) as performance metrics as these are the standard for generic ADC design. This paper studies the use of information-based metrics such as bit-error-rate (BER) to design a BER-optimal ADC (BOA) for serial links. Channel parameters such as the m-clustering value and the threshold non-uniformity metric ht are introduced and employed to quantify the BER improvement achieved by a BOA over a conventional uniform ADC (CUA) in a receiver. Analytical expressions for BER improvement are derived and validated through simulations. A prototype BOA is designed, fabricated and tested in a 1.2 V, 90 nm LP CMOS process to verify the results of this study. BOA's variable-threshold and variable-resolution configurations are implemented via an 8-bit single-core, multiple-output passive digital-to-analog converter (DAC), which incurs an additional power overhead of less than 0.1% (approximately 50 μW). Measurement results show examples in which the BER achieved by the 3-bit BOA receiver is lower by a factor of 109 and 1010, as compared to the 4-bit and 3-bit CUA receivers, respectively, at a data rate of 4-Gb/s and a transmitted signal amplitude of 180 mVppd.
A new CMOS output buffer with low switching noise and load adaptability is presented in this paper. By designing an innovative combination structure of two driving stages, the buffer can reduce switching noise and output ringing with no penalty on signal transmission speed. Furthermore, the buffer can automatically adjust the total driving capability in response to variation of loading condition, the load adaptive method is simple and effective without the necessity for a feedback circuit. The proposed buffer has been designed in a TSMC 90 nm CMOS process. Simulation results demonstrate that the proposed buffer achieves 4.1-53.5% improvements in ground bounce and 2.9-15.2% reductions in output ringing compared with those of the AC/DC buffer. Meanwhile, it reduces ground bounce by 6.5-17.6% and output ringing by 3.8-10.9% relative to the CSR buffer.
In this paper, an innovative efficiency-boosting technique is successfully applied to typical linear light emitting diode (LED) drivers. Furthermore, p-channel MOSFET (PMOS) pass element with elaborate metal layout pattern is used to reduce dropout loss and a 5V regulated voltage is obtained from the wide range input voltage to power some sub-circuits. This will further diminish power dissipation and thus enhance efficiency. The proposed driver has been fabricated on a 0.5µm Bipolar CMOS DMOS (BCD) process. process. Post-simulation results show that when driving three high brightness light emitting diodes (HB-LEDs) in series, it can achieve maximum efficiency of 91.12% at ILOAD = 350 mA, which is improved by 7.3%, as compared with that of the typical one under the same condition. Besides, the proposed driver is able to operate with a wide input voltage range (6V~32V) and deliver output current up to 350 mA, with an accuracy of ±3%, regardless of process voltage temperature (PVT) variations. Besides, the dropout voltage is only 450mV when ILOAD =350 mA and VIN =12V.