Image Source: tinyurl.com/45pry3rz
Cluster 1: Efficient LLMs/VLMs
Students: Yonggan Fu, Zhongzhi Yu, Haoran You, Zhifan Ye, and Chaojian Li
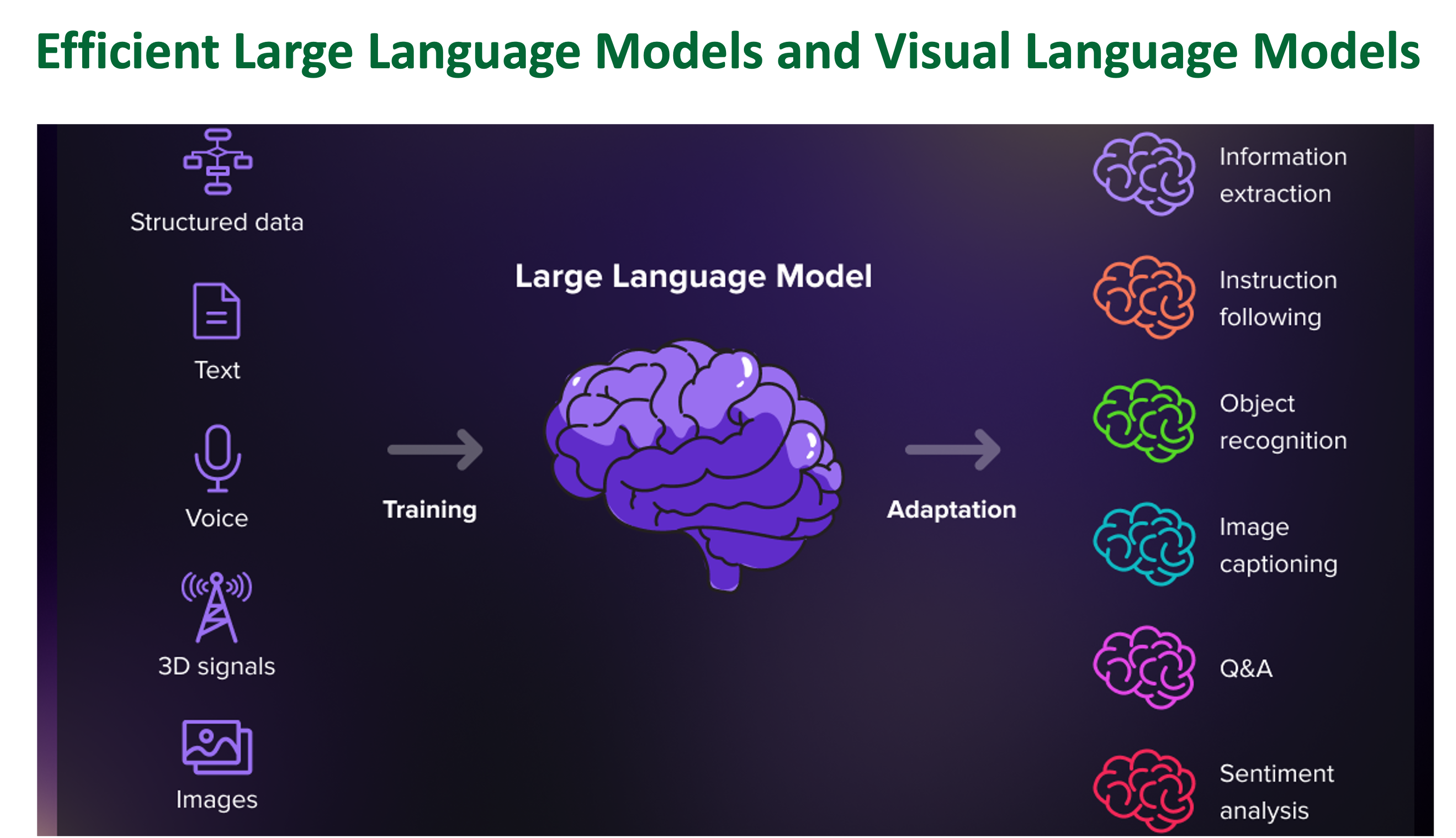
The rise of large language models (LLMs) and visual language models (VLMs) is transforming how we interact with technology, with the potential to reshape many aspects of our digital experiences.
However, this potential is accompanied by notable challenges. The high computational, memory, and energy demands associated with LLMs present substantial obstacles to realizing their full capacity in practical applications.
Our research is committed to addressing these challenges by developing efficient LLM/VLM solutions. Through rigorous research and real-world validation, we aim to enhance the efficiency and accessibility of LLM/VLM-driven technologies.
At the core of our mission is the ambition to extend the capabilities of LLMs/VLMs to new heights. We invite you to join us on this path as we work towards unlocking the full potential of LLMs/VLMs.
Corresponding Publications:
Cluster 2: ShiftAdd-Based Networks
Students: Haoran You, Huihong Shi, Yipin Guo, Wei Zhou, and Yang (Katie) Zhao
Multiplication, such as in convolutions, undoubtedly forms a cornerstone of modern deep neural networks (DNNs). However, the computational demands of intensive multiplications result in costly resource usage, posing challenges for deploying DNNs on resource-constrained edge devices. Consequently, various efforts have been made to devise multiplication-less deep networks.
In pursuit of this objective, we introduce ShiftAdd-Based Networks, drawing primary inspiration from a prevalent practice in energy-efficient hardware design. Specifically, we embrace the notion that multiplication can be substituted by additions and logical bit-shifts. We harness this concept to meticulously parameterize deep networks, yielding a fresh category of DNNs that exclusively incorporates bit-shift and additive weight layers. This hardware-inspired ShiftAddNet promptly delivers both energy-efficient inference and training, all the while preserving expressive capacity akin to standard DNNs. The twin operation modalities, namely bit-shift and addition, additionally empower precise modulation of the model's learning capacity. This, in turn, permits a more pliable balance between accuracy and training efficiency, and enhances resilience to quantization and pruning.
This innovative paradigm has been successfully applied across diverse networks, encompassing Convolutional Neural Networks and Transformers alike. Furthermore, we have developed accelerated kernels to facilitate tangible speed enhancements on GPUs, along with tailor-made accelerators that unlock its full potential.
Corresponding Publications:
Cluster 3: Distributed Training
Student: Cheng Wan
As machine learning rapidly advances, the size of both models and datasets is growing at an unprecedented rate. Our team is leading the way in addressing this challenge with innovative solutions for distributed training.
One of our key focuses has been improving communication efficiency in distributed training for graph neural networks (GNNs). Through a mix of deep theoretical research and thorough empirical testing, we’ve developed methods that significantly boost communication efficiency and speed up training convergence. Our work enables seamless training on graphs with up to 100 million nodes, expanding what’s possible in GNN-based learning.
We’re also accelerating distributed training for Transformer models, which are crucial for tasks in both language and vision. Our goal is to push the limits of speed and efficiency in training, helping researchers and practitioners tackle larger and more complex problems in language and image understanding and generation.
At the heart of our efforts is a commitment to advancing distributed training techniques to meet the growing demands of machine learning. Join us as we explore new frontiers, optimize training processes, and drive the evolution of machine learning in a world full of possibilities.
Corresponding Publications: